Tag: évaluation outils
Des ondes sonores aux résumés : l'analyse des podcasts par l'IA change la donne

Dans le paysage en constante expansion des podcasts, où des millions d’heures de contenu sont produites quotidiennement, une nouvelle frontière émerge. L’intelligence artificielle (IA), autrefois réservée à la science-fiction, révolutionne aujourd’hui la façon dont nous consommons le contenu audio. L’IA est entrée dans l’arène, offrant une solution révolutionnaire qui transforme le son brut en transcriptions et en résumés avec rapidité et précision.
Ce saut technologique n’est pas seulement une question de commodité, il remodèle tout le paysage de l’accessibilité des podcasts. Qu’il s’agisse de professionnels très occupés cherchant à obtenir rapidement les éléments importants ou de chercheurs réalisant du data mining, la capacité de l’IA à distiller des heures de conversation en extraits digestes est tout simplement incroyable.
Mais à quel point l’IA est-elle efficace dans cette tâche ?
Traduit de l’anglais par l’équipe de BASES PUBLICATIONS
L’IA peut-elle écrire à notre place ? le test des « styles » de Claude

Nous avions décrit dans la rubrique IA du dernier numéro de BASES comment utiliser la nouvelle fonctionnalité « styles rédactionnels » de Claude, dont la promesse est de produire un texte avec le « bon style de rédaction ».
Cette fonctionnalité est intéressante en soi, car elle nous emmène déjà au-delà de la « simple » génération de contenus, vers la création de textes toujours plus personnalisables, de qualité comparable à ceux que l’on produit manuellement et même, pourrait-on dire, « humanisés ».
Claude fait d’une certaine façon « coup double » avec cette fonctionnalité des styles personnalisés : elle concerne à la fois la rédaction d’un texte en imitant un auteur humain donné et l’adaptation du message au type de public cible.
L’art de la présentation à l’ère de l’IA pour les pros de l’info

Pour les professionnels de l’information, documentalistes, analystes ou chargés de veille stratégique, la production de présentations de grande qualité est devenue un must en termes de (re) présentation personnelle et de communication. Qu’il s’agisse de communiquer les résultats de leur veille, de leurs recherches ou de leurs activités, ils doivent choisir l’outil le plus adapté pour capter l’attention de leur audience et transmettre leur message avec clarté et efficacité.
L’irruption de l’IA dans la création de présentations
L’IA a fait irruption sur ce segment en apportant beaucoup de créativité en termes de graphisme, mais aussi de contenu. Il faut donc désormais examiner les outils de production graphique à l’aune de ces deux critères.
Avec la multiplication des outils et applications promettant monts et merveilles en matière de présentation, on peut être tenté de se précipiter sur le plus « marketé ».
Faire ses recherches avec un GPT

Utiliser un assistant IA monotâche comme les GPTs d’OpenAI permet d’utiliser un modèle de langage dans un but spécifique et de façon plus précise qu’avec un chatbot généraliste comme ChatGPT, Gemini ou Copilot. Nous en avons testé une vingtaine dédiés à la recherche et voici les résultats de notre sélection.
Les agents virtuels ne sont pas simplement capables de converser et de guider l’utilisateur comme un chatbot, mais ils peuvent aussi adapter leurs réponses au contexte et à l’intention de celui-ci.
Les plus connus sont les GPTs d’OpenAI, même si d’autres agents sont apparus comme les Hugging Chat Assistants de Hugging Face et les copilotes de Microsoft.
Mais les GPTs d’OpenAI, d’après nos tests, restent les plus opérationnels. Attention, ils ne sont toutefois disponibles qu’avec la version payante GPT Plus, pour un résultat qui reste inégal.
Second cerveau digital : jusqu’où Inoreader nous aide-t-il ?

Inoreader est un agrégateur de flux RSS connu des professionnels de la veille qui sont particulièrement concernés par l’idée de se constituer un « second cerveau ». Ce dernier est capable de mémoriser l’information importante tout en facilitant sa disponibilité pour l’utiliser quand cela s’avère nécessaire. Jusqu’où et comment cet outil de veille peut-il contribuer à cette démarche ? Voici une méthode pas à pas.
L’idée de se construire un « second cerveau » digital, sorte d’externalisation de sa mémoire informationnelle est ancienne. Elle a été popularisée récemment avec succès par Tiago Forte (voir à ce sujet les articles de Netsources N° 165 - juillet/août 2023). Sa démarche se divise en quatre étapes, réunies sous l’acronyme CODE : Capturer, Organiser, Distiller et Exprimer.
Lire aussi :
Que valent les outils de reconnaissance faciale pour la veille image ou l’investigation ? (Bases N°414 - mai 2023)
La veille et la recherche d’information à l’ère des « fake news » et de la désinformation (Netsources N°140 - mai/juin 2019)
Tirer parti du fact-checking et du journalisme d’investigation pour la veille et la recherche d’information (Netsources N°140 - mai/juin 2019)
Search : Arc ouvre la voie à de nouvelles pratiques de recherche

La nouvelle fonctionnalité de recherche IA « Browse for Me » du navigateur Arc n’est disponible que sur iPhone et elle fait déjà grand bruit.
Non seulement elle a été rapidement adoptée par les utilisateurs, mais la presse y voit une fonctionnalité qui réinvente la façon de s’informer… et pourrait être le pire cauchemar des éditeurs.
Pour les professionnels de la veille, son impact pourrait bien aller au-delà du Search.
Disponible depuis quelques mois sur Windows après avoir été adopté par les utilisateurs de Mac (voir notre article « Arc browser réinvente la navigation en ligne », BASES N° 420, décembre 2023), le navigateur Arc vient à nouveau d’attirer l’attention du monde de la tech avec sa nouvelle fonctionnalité « Browse for Me » (que l’on pourrait traduire en français par « cherche pour moi »).
Disponible uniquement sur les iPhones actuellement, le bouton « Browse for Me » apparaît au cours de l’écriture dans la barre de recherche (voir Figure 1).
Créer une newsletter avec Flashissue et MailChimp

Produit documentaire classique, la newsletter a su devenir incontournable pour proposer des services, mais aussi valoriser des activités et l’image du service documentaire. Nous avons expérimenté deux outils de création et diffusion de contenus, Flashissue et MailChimp.
La newsletter fait partie des produits documentaires « vitrine » du service. Elle permet de communiquer auprès des utilisateurs sur divers sujets : nouvelles acquisitions du fonds documentaire pour les bibliothécaires et documentalistes, actualités du service, voire un panorama de presse dans le respect du copyright, sans oublier la valorisation de son expertise et image.
Utiliser un outil dédié permet non seulement de gagner du temps sur la mise en page, mais aussi de professionnaliser la production de la newsletter.
Voici un retour d’expérience avec deux outils du marché : Flashissue et MailChimp.
FOCUS IA : générer un quiz en moins d’une minute

Pour rendre un livrable et une formation efficaces en vérifiant le niveau de compréhension de son public ou tout simplement pour rajouter une touche de divertissement, le quiz est un outil pédagogique qui peut s’avérer un précieux allié. Et aujourd’hui avec les modèles d’IA générative, un quiz peut être créé en une minute, ou presque. Florilège de nos 4 outils préférés.
Opexams, un quiz gratuit par jour
Opexams est une plateforme pédagogique qui propose la génération de quiz parmi d’autres fonctionnalités.
Son « Quiz Generator » est accessible sans inscription. Le quiz est généré à partir d’un texte à fournir (jusqu’à 3000 signes environ) et, comme toujours avec ces outils IA, le procédé est simplifié au maximum : on copie son texte, puis on sélectionne les options suivantes : le type de quiz (choix multiples, vrai/faux ou questions ouvertes), la langue, le nombre d’options par question (cinq maximum), puis on clique sur « Générer un quiz ».
L’option « par sujet » permet d’entrer uniquement un thème de son choix, qu’il soit dans le domaine scolaire ou professionnel. Aux options précédentes, s’ajoute le niveau de difficulté souhaité (facile/moyen/difficile).
Les nouvelles promesses de la recherche multilingue en action

Cela fait des années que l’on entend parler de Cross-Language Information Retrieval (CLIR) pour la recherche d’information. Il s’agit de la capacité à rechercher dans une langue et à recueillir des résultats dans d’autres langues. Jusqu’à maintenant, les produits ou fonctionnalités de ce type étaient rares et n’ont jamais véritablement décollé, à l’instar de la fonctionnalité proposée par Google de 2007 à 2013.
Et pourtant, il y a là un vrai besoin notamment pour les professionnels de l’information : dans un monde globalisé, il est en effet souvent nécessaire d’élargir à des sources en anglais (ce qui est souvent gérable), mais aussi à des sources dans des langues dont on ne maîtrise pas toujours les rudiments.
Si on peut malgré tout à mettre en place un système qui fonctionne en s’aidant de dictionnaires et d’outils de traduction, le processus reste long et fastidieux (voir Netsources N°163 - avril 2023 consacré à la veille multilingue).
Lire aussi :
Sourcing, de la théorie à l’épreuve de la pratique (Netsources N° 146 - mai/juin 2020)
Les nouvelles dimensions du multilinguisme pour la veille (Netsources N° 163 - mars/avril 2023)
Veille multilingue : comment trouver ses mots ? (Netsources N° 163 - mars/avril 2023)
Veille internationale : comment trouver des sources en langue étrangère ? (Netsources N° 163 - mars/avril 2023)
Comprendre les résultats de sa veille multilingue en un clin d’œil (Netsources N° 163 - mars/avril 2023)
Comment l’IA enrichit les livrables de veille multilingue ? (Netsources N° 163 - mars/avril 2023)
L’idéal dans cette situation serait de rechercher dans sa langue ou en anglais et de récupérer les contenus publiés dans d’autres langues, mais traduits en anglais ou français pour les analyser.
Bonne nouvelle : cela existe déjà, et c’est même en train de prendre de l’ampleur.
FOCUS IA : maîtriser et gérer ses prompts

S’il n’est pas la seule clé du succès pour garantir un résultat satisfaisant d’un outil IA, un bon prompt augmente néanmoins ses chances d’obtenir satisfaction. Des milliers d’outils permettent de copier, améliorer ou encore stocker ses prompts. Ils varient en fonction des algorithmes concernés, des thèmes et des formats à générer et/ou des usages. En voici quatre sur une trentaine testés, sélectionnés pour leur efficacité et leur facilité de prise en main : Prompt Genius, PromptBase, SnackPrompt et FlowGPT.
Lire aussi :
L’art du prompt pour le professionnel de l’information, Netsources N°164 - juin 2023
AI Prompt Genius, pour stocker ses prompts personnels
AI Prompt Genius s’adresse aux personnes ayant déjà trouvé des prompts (ou « invites » en français) qui répondent à leurs besoins et ont besoin de les stocker dans un endroit accessible quelle que soit l’IA générative utilisée. Plutôt qu’une longue liste ingérable, cette extension accessible sans inscription permet de créer sa propre bibliothèque de prompts.
Elle s’ouvre sur une barre de recherche au centre et les prompts sont rangés en dossiers dans la barre de gauche.
Pour stocker un prompt, on clique sur « Nouveau prompt » et une fenêtre s’ouvre. Les champs à remplir pour créer son prompt sont « Titre », Texte (avec les variables), Description, Étiquette et on sélectionne le nom du dossier.
Prompt Genius s’utilise sur toutes les plateformes. L’outil suggère de créer des dossiers en fonction du modèle de langage concerné (ChatGPT, Bard, DALL-E, etc.) et des étiquettes sur des tonalités différentes. Ce qui rappelle qu’un même prompt n’aura pas le même résultat avec des modèles différents. Et comme chaque modèle d’IA a son propre langage, les invites doivent s’adapter à chacune.
En termes d’ergonomie, il s’affiche soit en pop-up comme la plupart des extensions, soit en barre latérale à droite de l’écran, sur ordinateur ou sur mobile. Il est aussi possible d’importer des prompts au format CSV et de les exporter en CSV ou JSON. L’outil, souvent recommandé par les professionnels de l’information et qui s’avère facile à utiliser et pratique à l’usage, est gratuit et disponible en français.
Promptbase, le supermarché des prompts
Promptbase est LA Marketplace de prompts. Intuitivement, on y choisit son domaine d’usage (éditorial, marketing, création de logos, illustrations, etc.) et son thème (animal, santé, finances, etc.) ou le modèle de langage de l’IA générative utilisée (Midjourney, DALL-E, Stable Diffusion, GPT).
Matilda, le nouveau moteur académique sans IA

En septembre dernier, le nouveau moteur académique Matilda était officiellement lancé. Explorez ses fonctionnalités de recherche avancées, ses fonctionnalités de veille, son vaste corpus et découvrez comment il se positionne par rapports aux outils de recherche académique.
À l’origine du projet, une équipe de chercheurs français coordonnée par Didier Torny du CNRS qui a pour ambition « de redonner une place équitable aux contenus académiques exclus des outils propriétaires actuellement utilisés, WoS et Scopus » et de « permettre aux bibliothécaires et aux chercheurs d’exercer le plus grand contrôle possible dans la manière dont ils recherchent et réutilisent les informations textuelles et les métadonnées. »
Lire aussi :
La vague d’outils IA pour l’Information Scientifique et Technique (IST) (Bases N° 420 - dec 2023)
Consensus, un moteur académique dopé à l’IA (Bases N° 410 - jan 2023)
Zendy : un moteur académique 100 % open access (Bases N° 406 - sept 2022)
Elicit, un nouveau moteur scientifique au banc d’essai (Bases N° 404 - juin 2022)
Comment faire évoluer sa recherche d’information scientifique avec les nouveautés de Google Scholar ? (Bases N° 404 - juin 2022)
Quel corpus ?
Premier aspect important : le corpus. Matilda se base sur la littérature scientifique indexée depuis 2019 dans Crossref, Pubmed Central, ArXiv et RePec soit plus de 128 millions d’articles. À cela s’ajoutent les données d’auteurs venant d’ORCID, et les articles référencés dans Unpaywall et pour lesquels on a directement accès au texte intégral.
Pour chaque article, on dispose des citations et références si elles sont disponibles.
Comment utiliser Threads pour la recherche et la surveillance de l’information ?

Threads, le réseau de micro-blogging de Meta, est accessible en France depuis quelques semaines. Le public commence à s’y rendre, y faire sa veille peut-il donc devenir intéressant ?
Threads a été créé par Meta en juillet 2023. Lancé au départ aux États-Unis, il lui a fallu plusieurs mois pour se conformer à la législation européenne. S’il a très vite dépassé les 100 millions d’utilisateurs, laissant croire à une relève assurée de X (ex. Twitter), les chiffres sont aussi très vite retombés et le manque de fonctionnalités essentielles perdure. Le terme Threads désigne ces longs fils de discussions - un post et les commentaires auxquels il donne lieu - apparus pour la première fois sur X.
Lire aussi :
Blueskyredessine la veille en feeds (Bases N° 418 - oct 2023)
Les veilleurs face au déclin de X (Twitter) - Brève de veille de novembre (nov 2023)
La veille sur les réseaux sociaux s’annonce de plus en plus fragmentée (Bases N° 417- sept 2023)
Quelques spécificités par rapport à X :
- La limite d’un post (appelé thread) est de 500 caractères et 5 minutes par vidéo,
- Les publications peuvent être modifiées dans un délai de 5 minutes (uniquement le texte, pas les pièces jointes),
- La description visuelle des photos et des vidéos pour les populations malvoyantes est automatique (mais modifiable),
- Le nombre de mentions « J’aime » sur les publications peut être masqué,
- L’insertion de sondages est prise en charge.
Lors de l’inscription, il est requis d’avoir un compte Instagram pour publier et interagir (voir Figure 1). Sans « Insta », on peut uniquement consulter des contenus et rechercher des comptes. Ce choix est réversible à tout moment, tout comme la possibilité d’avoir un profil public ou privé (cette deuxième option s’applique par défaut pour les moins de 18 ans). On peut en effet créer son compte en public (tout le monde peut nous voir et nous suivre) ou en privé.
FOCUS IA : écrire avec l'assistance d'un outil d'IA

Même s’ils n’écrivent pas à votre place, les outils d’editing issus des IA génératives de texte peuvent être de précieux alliés pour titrer ou réécrire ses livrables. Parmi nos préférés, Headline Hero, Quillbot, Hemingway et TextCortex. À noter qu’ils sont tous à utiliser sur sa propre prose, et non à des fins de plagiat. Entre correction guidée et réécriture, ils proposent différents niveaux d’intervention. Voici les informations clés pour aider à choisir le plus pertinent pour soi.
Headline Hero, pour trouver le juste titre
HeadlineHero est le chouchou des rédactions américaines. Et même s’il est en anglais, il fonctionne aussi très bien en langue française.
Quelle que soit la nature du texte à titrer (analyse d’un livrable, revue de presse sous forme de newsletter, etc.), il suffit de se rendre sur le site internet, de copier un extrait de son texte sur l’espace réservé à cela (à droite de l’écran), choisir la longueur de son titre (le nombre de mots souhaité) et de cliquer sur Generate Headlines pour voir plusieurs propositions de titres apparaître à la place de son texte précédemment copié, qui s’est lui-même déplacé sous les titres (voir Figure 1).
ARC Browser réinvente la navigation en ligne

Depuis quelques mois, un nouveau navigateur baptisé Arc est souvent évoqué comme une alternative à Chrome non seulement crédible, mais salutaire. Nous avons donc testé ce nouveau navigateur, accessible jusqu’alors à tous les utilisateurs de Mac, rejoints depuis ce mois-ci par les premiers utilisateurs de Windows PC inscrits sur liste d’attente. Spoiler : on a très vite oublié Chrome.
Le navigateur Arc a été créé par The Browser Company, une société américaine créée en 2019 qui réunit d’anciens salariés d’Instagram, Amazon, ou encore… Google Chrome. Josh Miller et Hursh Agrawal, de leur côté, avaient revendu une précédente startup à Facebook en 2014.
Comme beaucoup de professionnels de la veille, on a déjà testé de nombreux navigateurs, mais le nombre d’extensions utilisées sur Chrome uniquement ne rend pas le départ aisé. Or, c’est un premier frein important levé par Arc.
Europe PMC, une banque de données augmentée en sciences de la vie

Il existe de très nombreuses banques de données bibliographiques de littérature scientifique. Selon les cas, les possibilités de recherche sont plutôt rustiques ou, au contraire, plus ou moins sophistiquées (indexation, opérateurs de proximité, troncatures, conversion des orthographes américaine et anglaises, reconnaissance des abréviations, recherche sur des valeurs numériques, liens citants/cités, recherche par structures chimiques, recherche dans plusieurs banques de données à la fois…).
Europe PMC va plus loin même si elle n’offre pas toutes ces possibilités et nous n’hésitons pas à la qualifier de banque de données augmentée car elle permet, d’une part, de focaliser la recherche sur certaines parties d’un article, par exemple les éléments de méthodologie ou les figures. Elle permet aussi, ce qui est original, d’établir, à partir du contenu d’une référence des liens avec plusieurs banques de données externes plutôt factuelles/numériques, spécialisées dans le domaine des sciences de la vie telles que ChEMBL-small molecules ou MGnify-Metagenomics.
FOCUS IA : notre sélection pour résumer et interroger des vidéos YouTube

Pour ce nouvel article de « Focus IA », nous avons décidé de nous intéresser spécifiquement aux outils qui permettent de résumer et d’interroger des vidéos YouTube.
Nous avons identifié une vingtaine d’outils répondant à nos critères et nous les avons tous testés sur quatre vidéos : une vidéo d’actualité en français émanant d’un grand média français et une autre en anglais émanant d’un média américain, un webinaire d’une heure proposé par un éditeur de veille en français et enfin une vidéo tech en anglais recommandant plusieurs extensions ChatGPT.
Parmi la vingtaine d’outils, nombreux sont très décevants mais quatre sortent du lot et produisent des résultats intéressants pour les professionnels de l’information. Voici notre sélection !
Lire aussi :
Les meilleurs outils IA pour résumer et interroger les contenus de la veille (Netsources N° 164 - mai/juin 2023)
Notre sélection d’annuaires d'outils IA - Article en accès libre (Bases N° 414 - mai 2023)
Comment intégrer YouTube dans votre dispositif de veille (Netsources N° 157 - mars/avril 2022)
Nous avons testé Azure Video Indexer, un outil puissant pour les transcriptions automatiques de vidéos et podcasts (Bases N° 403 - mai 2022)
Les nouveaux outils de dataviz pour explorer la littérature scientifique

Il y a quelques années, on avait pu voir émerger des outils d’exploration des réseaux de citations des articles scientifiques. Ces outils s’avèrent très utiles pour trouver des articles scientifiques pertinents que l’on n’aurait pas forcément identifiés lors d’une recherche par mot-clé classique et sont donc complémentaires aux moteurs académiques.
Parmi cette première génération d’outils, il existait deux grandes catégories : ceux qui étaient visuels proposant donc une représentation graphique, et ceux qui étaient uniquement textuels
Voir notre article « La recherche de citations et de références boostées par l’IA et les “open citations” », Bases N° 369 - avril 2019.
Si les outils textuels ont bien résisté et ont aujourd’hui une place de choix dans le paysage de l’IST, les outils visuels n’ont pour la plupart pas eu le même destin. Parmi les outils de dataviz de première génération, on comptait des acteurs comme Citigraph, Yewno ou encore Citation Gecko, qui ont tous fermé leurs portes. Dans cette catégorie, seul VosViewer continue sa route et a été intégré très discrètement au moteur académique Dimensions.
Au cours des deux dernières années, une nouvelle génération d’outils visuels d’exploration des réseaux de citations est apparue, avec une petite dizaine d’acteurs cette fois-ci, toujours portée par l’amplification du mouvement de l’open (open access et open citations) dans le monde académique.
Dans cet article, nous dressons un panorama de ces différents outils et de leurs spécificités. Nous les avons également tous testés pour évaluer leur performance et vous aider à faire le bon choix.
FOCUS IA : notre sélection d’annuaires d'outils IA - article en accès libre

On découvre chaque jour, dans la déferlante des applis, extensions et plug-ins, tout le potentiel de ChatGPT et de l’IA pour nos métiers de l’information. Malgré les réserves très compréhensibles que l’on peut avoir, on ne peut nier l’intérêt de ces puissants modèles d’intelligence linguistique pour l’ensemble des opérations de traitement des données qui sont pour partie le socle de la veille et de l’activité documentaire.
Nul doute que le professionnel de l’information doive évaluer tous les outils en fonction de leur apport technique et fonctionnel sur l’ensemble de la chaîne de valeur des opérations. Leur intégration conduit progressivement à l’optimisation, voire le ré-engineering, des processus internes.
● Face aux enjeux, nos méthodologies et recommandations d’outils dans BASES et NETSOURCES intègrent de plus en plus les contributions des premières IA commercialisées. À titre d'exemple : la « Revue des moteurs de recherche à l’heure de ChatGPT », Bases N°413 - avril 2023, et notre prochain NETSOURCES dédié à ChatGPT et autres outils d'IA.
● Nous consacrerons désormais notre rubrique ACTUALITES à l’exploration des outils «du moment» dans un domaine fonctionnel donné, afin de sortir des discours euphoriques et faire émerger ceux qui nous paraissent les plus prometteurs dans un contexte incertain.
Nous avons décidé de commencer cette nouvelle série d’articles par les nouveaux annuaires IA car c’est une des portes d’entrée de choix vers les nouveaux outils dopés à l’IA générative. Parmi les nombreux annuaires sur le marché, nous en avons sélectionné quatre que nous avons jugés les plus pertinents.
OpenAlex, un nouveau moteur académique

OpenAlex est un nouvel outil qui vient se positionner sur le créneau de Google Scholar, Dimensions, Lens.org et les autres. Son but : devenir un catalogue qui recense un maximum de publications scientifiques, mais aussi chercheurs et institutions, une sorte de bibliothèque d’Alexandrie de l’IST version Web.
OpenAlex est un projet de l’organisation à but non lucratif OurResearch financé par Arcadia, un fonds qui œuvre pour la préservation de la culture et la promotion du libre accès.
Nous avons testé la version Alpha (la bêta sortira en juillet prochain) pour savoir ce qu’elle avait à nous offrir et quelle pouvait être sa valeur ajoutée par rapport aux outils déjà en place.
Lire aussi :
De nouveaux moteurs gratuits pour concurrencer Google Scholar (September 2018)
Elicit, un nouveau moteur scientifique au banc d’essai (Bases N° 404 - juin 2022)
Déconstruction de l’article scientifique : une nouvelle façon de rechercher l’information ? (Bases N° 409 - dec 2022)
Recherche bibliographique : moteurs gratuits ou grands serveurs payants, que choisir ? (Bases N° 405 - juil/août 2022)
Comment faire évoluer sa recherche d’information scientifique avec les nouveautés de Google Scholar ? (Bases N° 404 - juin 2022)
La dataviz n’est pas un long fleuve tranquille : l’exemple de Gephi pour cartographier Twitter
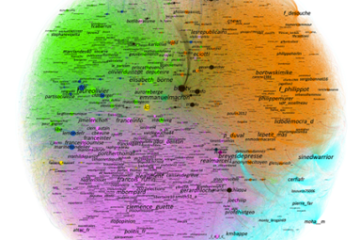
La dataviz semble désormais être partout dans notre monde de l’information professionnelle, dans les demandes des clients et… dans les plateformes de veille.
Cette irruption du quantitatif, de l’analytique et du visuel dans des masses d’information documentaire longtemps sous-exploitées est à notre sens extrêmement positive, tant l’extraction et l’interprétation des données, rendue possible par la dataviz, donnent du sens à celles-ci et valorisent le travail de collecte et capitalisation des professionnels de l’information et de la veille.
Mais attention, utiliser la cartographie dans le but d’embellir une présentation ou, pire, en faire un argument de vente à une direction d’entreprise en promettant de générer «automatiquement» du sens via des graphes et représentations diverses, est en soi une aberration trop souvent observée… La dataviz comme pensée «automatisée», voire magique, est un facteur de risque, de contresens et confusion.
Légifrance améliore ses fonctionnalités de recherche

Depuis la mise à jour du moteur en juillet dernier (et le remplacement de son interface), nombreux sont les professionnels qui regrettent l’ancienne interface.
Qu’à cela ne tienne, Légifrance a procédé à quelques améliorations récemment au niveau de la recherche. Outre une dizaine de corrections de bugs, on notera les nouveautés suivantes :
- Interprétation du tiret comme un espace dans la recherche (par exemple, les recherches Mont-Saint-Michel et Mont-Saint-Michel sont interprétées de la même façon et donnent la même liste de résultats) ;
- Amélioration du surlignement dans les résultats de recherche ;
- Ajout des plans de classement de la jurisprudence administrative et de la jurisprudence judiciaire ;
Quels outils utiliser pour bénéficier de ChatGPT ?

Nul n’a pu y échapper. Dans les médias, au bureau… on ne parle que de cela : ChatGPT est-il en train de ringardiser Google ?
Au regard de la recherche d’informations, ChatGPT n’est pourtant pas assez fiable pour être utilisé de façon professionnelle. D’ailleurs, ce bot conversationnel n’a pas vocation à devenir un moteur de recherche. En revanche, son impact sur la recherche d’information est réel et il est intéressant d’explorer dès maintenant les usages en la matière, en ce qu’ils préfigurent ceux des années à venir.
Difficile de résumer ChatGPT, un bot gonflé à l’intelligence artificielle, à une seule fonctionnalité : créateur de contenu (et de code), moteur de réponse, traducteur, générateur de résumé… ChatGPT fait tout cela à la fois. Il peut donc être utilisé à chaque étape de la veille, qu’il s’agisse de l’identification des besoins, du sourcing, ou de l’analyse.
Pourquoi est-il populaire ? Du fait de son interface de dialogue simplifiée, à laquelle on accède après inscription. Une fois cette formalité établie, une barre de dialogue s’ouvre en bas de page. C’est là que l’on pose ses questions. L’outil y répond en haut et la conversation défile, comme une conversation avec n’importe quel chatbot.
Google améliore la recherche : le point sur les nouvelles fonctionnalités
L’innovation et l’actualité chez Google ne s’arrêtent jamais et ces derniers mois ne dérogent pas à la règle.
Dans cet article, nous faisons le point sur ces innovations récentes et nous testons les fonctionnalités et les produits, dans une perspective de veille et de recherche professionnelles.
Les nouvelles fonctionnalités utiles pour le pro de l’info
En septembre dernier, Google a animé son rendez-vous annuel Search-On où il dévoile toutes ses nouveautés en lien avec son moteur et la recherche d’information.
À cette occasion, nous avons découvert de nouvelles fonctionnalités intéressantes.
Un nouvel usage des guillemets dans Google
Les guillemets dans Google ont toujours servi à rechercher des expressions exactes même si cela n’empêche pas Google de passer outre, de temps à autre, quand il le juge nécessaire.
L’usage des guillemets a récemment évolué, mais c’est au niveau des résultats que cela fait une différence. Les guillemets permettent toujours de rechercher une expression exacte, mais dans les résultats proposés, on peut maintenant visualiser un extrait du contenu contenant spécifiquement cette expression, ce qui permet donc de voir dans quel contexte l’expression est utilisée et déterminer la pertinence du résultat par rapport à ses besoins.
Lire aussi :
Nous avons testé Kagi Search, un nouveau challenger de Google (Bases N° 407 - oct 2022)
Nous avons testé Neeva, le moteur qui pourrait remplacer Google chez les pros de l’info (Bases N° 406 - sept 2022)
Nous avons testé 6 agrégateurs de flux RSS méconnus pour la veille

Si Feedly et Inoreader sont aujourd’hui les deux lecteurs RSS les plus plébiscités pour la veille (non sans raison), ils ne conviennent pas nécessairement à tout le monde : soit en raison du prix qui ne cesse d’augmenter avec les années, soit en termes d’hébergement et de sécurité des données (certaines entreprises n’autorisent pas l’utilisation de certains outils hébergés en ligne), soit en termes de fonctionnalités (ils en ont beaucoup pour la veille, mais ne peuvent couvrir l’ensemble des besoins).
Pour cet article, nous avons sélectionné 6 agrégateurs de flux RSS parmi tous ceux sur le marché qui sont sur le papier les plus prometteurs et intéressants pour toute personne faisant de la veille : Feedbro, Fresh RSS, New Sloth, Feedbin, Newsblur et Feeder.
Nous les avons testés, avons évalué leur potentiel pour le veilleur et avons analysé leurs particularités et leur valeur ajoutée par rapport aux autres outils du marché et notamment Feedly et Inoreader.
Lire aussi :
Maîtriser le RSS, le socle inamovible de la veille (Netsources N°159 - juillet/août 2022)
Comment choisir la méthode la plus adaptée pour mettre une source en veille à partir d'un flux RSS (Netsources N°159 - juillet/août 2022)
Comment récupérer un flux RSS sur la majorité des sites web ? (Netsources N°159 - juillet/août 2022)
Comment récupérer des flux RSS sur les réseaux sociaux ? (Netsources N°159 - juillet/août 2022)
Comment transformer une newsletter en flux RSS ? (Netsources N°159 - juillet/août 2022)
Comment récupérer un flux RSS sur les moteurs web et Google Actualités ? (Netsources N°159 - juillet/août 2022)
Découvrir et maîtriser les dernières innovations d’Inoreader
Conçu il y a 10 ans, Inoreader, est l’un des rares agrégateurs qui permet d’aller le plus loin avec les flux RSS et réellement faire de la veille.
Ses utilisateurs connaissent déjà les fonctionnalités qui ont assuré son succès, comme les « règles », pour automatiser le filtrage par mots-clés, le classement par « tags » ou « à lire plus tard », mais aussi la recherche et la surveillance facilitée de Google Actualités dans 25 langues, la « tasse à café » pour lire un article gratuit dans son intégralité ou encore la suppression des doublons. C’est l’une des raisons pour lesquelles il est l’outil privilégié des professionnels de l’information qui souhaitent maitriser leurs flux.
Sa tarification est une autre raison. Depuis sa création, Inoreader ne cesse de proposer de nouvelles fonctionnalités très utiles pour la veille, ce qui le hisse peu à peu en véritable concurrent frontal de certaines plateformes de veille... pour un budget beaucoup plus réduit. Si l’abonnement Pro est accessible à moins de 9 euros par mois, il faut cependant savoir que ses fonctionnalités les plus évoluées sont limitées en nombre. Il est toujours possible d’en acheter davantage pour compléter son dispositif, ce qui augmente le prix de l’abonnement, qui reste malgré tout bien en-deçà des propositions alternatives sur le marché
Inoreader est aujourd’hui doté d’au moins quatre avantages concurrentiels: la création de flux RSS, l’écoute de sa veille sous forme de playlist, son « moteur de recherche personnalisé » et sa newsletter automatique.
Lire aussi :
Maîtriser le RSS, le socle inamovible de la veille (Netsources N° 159 - juil/août 2022)
Comment choisir la méthode la plus adaptée pour mettre une source en veille à partir d'un flux RSS (Netsources N° 159 - juil/août 2022)
Comment récupérer un flux RSS sur la majorité des sites web ? (Netsources N° 153 - juil/août 2021)
Comment récupérer des flux RSS sur les réseaux sociaux ? (Netsources N° 159 - juil/août 2022)
Comment transformer une newsletter en flux RSS ? (Netsources N° 159 - juil/août 2022)
Comment récupérer un flux RSS sur les moteurs web et Google Actualités ? (Netsources N° 159 - juil/août 2022)
Quels critères pour bien choisir un lecteur RSS pour sa veille ?

Quand on réalise une veille pour soi-même (dans le cas d’une veille métier par exemple), des veilles qui ne nécessitent pas des milliers de sources, qui génèrent un volume d’information raisonnable ou qu’on dispose d’un budget limité, les lecteurs de flux RSS sont toujours aujourd’hui des outils incontournables.
Mais il n’est pas toujours simple de choisir parmi tous les lecteurs/agrégateurs les plus adaptés pour la veille, car il y a de nombreux critères à prendre en compte.
C’est ce que nous explorons dans cet article.
Lire aussi :
Maîtriser le RSS, le socle inamovible de la veille (Netsources N° 159 - juillet/août 2022)
Comment choisir la méthode la plus adaptée pour mettre une source en veille à partir d'un flux RSS (Netsources N° 159 - juillet/août 2022)
Comment récupérer un flux RSS sur la majorité des sites web ? (Netsources N° 159 - juillet/août 2022)
Comment récupérer des flux RSS sur les réseaux sociaux ? (Netsources N° 159 - juillet/août 2022)
Comment transformer une newsletter en flux RSS ? (Netsources N° 159 - juillet/août 2022)
Comment récupérer un flux RSS sur les moteurs web et Google Actualités ? (Netsources N° 159 - juillet/août 2022)
Exploiter tout le potentiel de Feedly pour la veille et la recherche d’information

Feedly est aujourd’hui un des lecteurs RSS les plus utilisés par les veilleurs et professionnels de l’information. Et ce n’est pas sans raison. Il propose en effet de nombreuses fonctionnalités qui répondent aux besoins des pros de l’information.
Le Feedly d’aujourd’hui n’a plus grand-chose à voir avec l’outil lancé en 2008. Au départ, Feedly est un lecteur de flux RSS gratuit proposant des fonctionnalités on ne peut plus basiques. L’outil reste relativement méconnu pendant des années, jusqu’à la disparition de Google Reader, lorsqu’il réussira intelligemment à se positionner comme alternative à Google Reader.
Avec les années, Feedly a su ajouter de nombreuses fonctionnalités utiles à toute personne faisant de la veille, mais semble de plus en plus vouloir se tourner vers d’autres types de publics.
Dans cet article, nous explorons en détail les fonctionnalités de Feedly afin de pouvoir l’utiliser au maximum de ses possibilités dans un contexte de veille, mais aussi de recherche d’information.
Lire aussi :
Maîtriser le RSS, le socle inamovible de la veille (Netsources N°159 - juillet/août 2022)
Comment choisir la méthode la plus adaptée pour mettre une source en veille à partir d'un flux RSS (Netsources N°159 - juillet/août 2022)
Comment récupérer un flux RSS sur la majorité des sites web ? (Netsources N°159 - juillet/août 2022)
Comment récupérer des flux RSS sur les réseaux sociaux ? (Netsources N°159 - juillet/août 2022)
Comment transformer une newsletter en flux RSS ? (Netsources N°159 - juillet/août 2022)
Comment récupérer un flux RSS sur les moteurs web et Google Actualités ? (Netsources N°159 - juillet/août 2022)
Nous avons testé Kagi Search, un nouveau challenger de Google

L’heure est indéniablement aux bonnes nouvelles du côté des moteurs. Alors qu’il n’y avait jusqu’à présent aucune alternative crédible à Google sur le terrain des moteurs Web pour la veille et la recherche d’information professionnelle, on voit enfin arriver sur le marché une nouvelle génération de moteurs en phase avec les problématiques des professionnels de l’information.
Après le lancement du très prometteur Neeva (voir notre article « Nous avons testé Neeva, le moteur qui pourrait remplacer Google chez les pros de l’info », Bases N° 406 - sept 2022) voici venir un autre moteur tout aussi intéressant appelé Kagi Search.
Kagi a lui aussi opté pour un positionnement où la qualité des résultats et de la recherche et le respect de la vie privée priment. Et ce choix passe également par un modèle économique freemium.
Dans cet article, nous présentons en détail ce nouveau moteur, son positionnement et ses fonctionnalités et nous évaluons sa capacité à intégrer la panoplie des veilleurs et des professionnels de l’information.
Lire aussi :
Nous avons testé Neeva, le moteur qui pourrait remplacer Google chez les pros de l’info (Bases N° 406 - sept 2022)
Utiliser la fonctionnalité Goggles de Brave Search en complément de Google CSE (Bases N° 406 - sept 2022)
Nous avons testé Yep.com, un nouveau moteur de recherche à l’index maison (Bases N° 405 - août 2022)
La renaissance des annuaires sur le Web : comment les identifier et les utiliser pour vos veilles et recherches ? (Bases N° 402 - avril 2022)
Nous avons testé Neeva, le moteur qui pourrait remplacer Google chez les pros de l’info

Cela fait 20 ans que de nouveaux moteurs apparaissent avec pour ambition de concurrencer voire détrôner Google. Et pratiquement tous ont le même créneau : le respect de la vie privée, domaine où il est clair que Google n’excelle pas.
Quand on recherche de l’information dans un contexte professionnel, le respect de la vie privée est certes important, mais il faut aussi pouvoir obtenir des résultats pertinents et de qualité et avoir à disposition des fonctionnalités de recherche dignes de ce nom. Et c’est malheureusement rarement le cas des différents moteurs que nous avons pu tester ces dernières années tels que Qwant, DuckDuckGo, Yep.com ou encore You.
Un nouvel entrant pourrait bien venir changer les règles du jeu dans le monde des moteurs grâce à sa bonne compréhension des requêtes et la qualité de ses résultats.
Il s’agit du moteur Neeva qui arrive enfin en Europe après avoir été lancé aux États-Unis en 2021. Et le moins que l’on puisse dire, c’est que ce moteur a de très nombreuses qualités, allant de la longue expérience de ses fondateurs chez Google à des fonctionnalités qui servent vraiment les professionnels de l’information.
Zendy : un moteur académique 100 % open access

Zendy est un moteur académique qui a été lancé il y a quelques années, mais qui reste méconnu en France (cf. figure 1. Interface de Zendy).
L’idée de départ est de rendre plus accessible la littérature académique notamment dans les pays et régions où il est difficile de souscrire à des bases de données et serveurs payants.
Développé par Knowledge E, une société basée à Dubaï qui propose des solutions de bibliothèques numériques, Zendy a donc noué des partenariats avec de grands acteurs de l’édition académique pour indexer leurs contenus et en mettre une partie gratuitement à disposition de ses utilisateurs.
Lire aussi :
Elicit, un nouveau moteur scientifique au banc d’essai (06/2022)




















