Sélectionner le numéro de "Bases" à afficher
« 80 % de l’information technique se trouve seulement dans les brevets » : vrai ou faux ?


Voilà des dizaines d’années qu’on lit cette expression dans de multiples documents de toutes natures ou qu’on l’entend prononcée lors de conférences. Pour illustrer la « popularité » de cette expression, une recherche dans Google avec l’expression « 80% of technical information is found only in patents » génère entre 8 et 10 millions de réponses. Si l’on cherche avec l’expression traduite en français, le nombre de documents annoncés est proche de 200 000 ! On sait que l’on ne pourra les visualiser tous, mais le chiffre est impressionnant.
Il faut noter que, si le plus souvent on parle de 80 %, on trouve également la fourchette « 70 % - 90 % ».
Dans cet article, nous nous sommes demandé s’il s’agissait d’une « légende urbaine persistante » ou bien si cela était vrai.
Des citations multiples dans la littérature scientifique et la littérature grise
Nous avons donc regardé quelques documents citant cette expression. Ils sont, à l’évidence, loin d’être issus de revues prédatrices ou de blogs farfelus puisque l’on trouve cette assertion aussi bien dans des conférences que par exemple dans les publications des organismes suivants :
- l’OEB en 2007 à l’adresse,
- l’OMPI,
- l’INPI en 2017 à la page 10 du document «Tout ce qu’il faut savoir avant de déposer un brevet».
- le Copyright Clearance Center (document de 2020 qui cite l’OEB).
- le quotidien français Les Echos (24 mars 1998 et 22 septembre 1999, 7 juin 2018 exprimé par un conseil en brevet qui parlait de 70 à 80 %). On en trouve même une mention en 2008 dans le Soleil de Dakar par le directeur de cabinet du ministre de l’Industrie du Sénégal.
On trouve aussi des citations plus récentes, par exemple dans un communiqué de presse de LexisNexis daté du 23 juillet de cette année ou encore, actuellement, sur le site de l’URFIST Paris.
Mais quelle peut bien être la source de cette information ?

Déjà abonné ? Connectez-vous...
La veille sur les réseaux sociaux s’annonce de plus en plus fragmentée

Le réseau social par excellence pour faire de la veille a longtemps été Twitter (désormais X), en raison des fonctionnalités qu’il proposait et de la gratuité de son API qui permettait l’existence d’un écosystème d’outils de qualité pour analyser, rechercher et faire de la veille sur le réseau social.
Et cerise sur le gâteau, on y trouvait de nombreux contenus pertinents pour la veille professionnelle. X (ex-Twitter) était à la fois une plateforme de communication des entreprises, des marques, des associations et des collectivités, le lieu d’expression de la communauté scientifique ou encore des journalistes, une place de choix pour la veille métier des veilleurs, un outil de recherche fiable sans algorithme de sélection avec des archives remontant à 2006, etc.
La fin de la gratuité de l’API et les évolutions des fonctionnalités ont brutalement mis un terme à la veille et à l’analyse automatisée telle qu’on pouvait les connaître. X (ex-Twitter) est devenu un réseau social fermé, comme beaucoup d’autres.
Et cela a des conséquences directes pour le pro de l’information : il faut envisager la veille sur les réseaux sociaux d’une autre manière, où X (ex-Twitter) est devenu un réseau social parmi d’autres dans la liste toujours plus longue des réseaux.
Dans cet article, nous vous expliquons comment faire de la veille sur les réseaux sociaux dans un contexte où, a priori, tous les réseaux sociaux peuvent avoir un intérêt pour la veille. Quels réseaux envisager, quels éléments mettre sous surveillance et quelle méthodologie appliquer et quels outils utiliser ?
Pourquoi fait-on de la veille sur les réseaux sociaux ?
Si on intègre les réseaux sociaux dans sa veille, c’est parce qu’on y trouve des informations que l’on ne trouve pas ailleurs ou alors difficilement.
- Les marques, les entreprises ou toute organisation (collectivités, associations, etc.) utilisent les réseaux sociaux comme moyen de communication ou de publicité.
- Les professionnels d’un secteur et les communautés peuvent y partager des contenus pertinents, de bonnes pratiques, des astuces ou encore des conseils, échanger avec leurs pairs.
- Enfin, certains les utilisent comme des plateformes de publication où ils peuvent créer des contenus originaux.
Et aujourd’hui, tout ce petit monde se retrouve dispatché sur différents réseaux sociaux. Il n’y a pas UN réseau social où la majorité des internautes ont une présence et y publient régulièrement tous leurs contenus. En revanche on observe qu’il existe des regroupements thématiques sur certains réseaux sociaux.
Où sont aujourd’hui les communautés et contenus pertinents pour la veille ?
Une récente étude du blog du Modérateur auprès des Community managers, qui sont généralement la voix des marques et des entreprises, montre que les réseaux les plus privilégiés par ces derniers en 2023 sont Instagram (79 % estiment qu’Instagram est important pour leur travail), LinkedIn (77 %), Facebook (70 %). X (ex-Twitter) n’arrive qu’en 6e position après YouTube et TikTok avec 27 % seulement des Community managers qui estiment qu’il est important pour leur travail.
Du côté d’autres communautés de professionnels ou d’experts, ce n’est pas nécessairement le même constat.
Du côté de la communauté scientifique, la revue Nature a récemment mené une enquête auprès de 170 000 scientifiques dont 9 200 ont accepté de répondre aux questions pour savoir comment avait évolué leur usage de Twitter.
Il ressort de cette enquête qu’un peu plus de 50 % avaient diminué le temps qu’ils passaient sur X (ex-Twitter) ; qu’un peu moins de 7 % avaient définitivement quitté le réseau social et que 46 % avaient également rejoint d’autres réseaux sociaux (Mastodon, LinkedIn, Instagram, Threads ou encore Facebook en tête de liste).
Et même si globalement, les répondants ne sont pas en accord avec les évolutions de X (ex-Twitter), beaucoup restent, par peur de perdre le réseau qu’ils ont mis tant de temps à construire. Et ceux qui sont partis privilégient avant tout Mastodon, loin devant les autres réseaux sociaux.
Du côté de la communauté des journalistes, c’est encore un peu flou. Même si l’on voit de nombreux articles qui évoquent la volonté de quitter X (ex-Twitter), aucun chiffre ne permet de matérialiser une fuite réelle. Certains médias sont actuellement en phase d’expérimentation avant de prendre une décision à l’image de la BBC, qui tente une expérimentation sur Mastodon pendant six mois. On ne négligera pas non plus le fait que de nombreux journalistes proposent désormais des newsletters depuis des plateformes comme Substack et en profitent pour se distancer des réseaux sociaux.
Concernant les experts de l’OSINT, on constate qu’un nombre non négligeable de professionnels se retrouvent sur Discord
Voir notre article « Comment utiliser Discord pour ses veilles et ses recherches ? » dans ce même numéro
Enfin, pour les professionnels de l’information, si l’on prend l’exemple des nombreux comptes que nous suivons pour notre veille sur la veille, l’heure semble pour le moment à la réflexion. Il y avait une très forte communauté sur X (ex-Twitter) depuis très longtemps, puis une deuxième qui s’était progressivement créée sur LinkedIn. Aujourd’hui, ceux qui sont encore sur X (ex-Twitter) se posent très régulièrement la question de leur place sur la plateforme. Parmi les comptes que nous suivons, nous constatons que quelques comptes-clés ont quitté la plateforme mais ces derniers restent peu nombreux. Les autres comptes intéressants publient toujours, mais certains ont quand même réduit la voilure : ils publient moins de contenus et moins souvent. Enfin, on note une baisse de l’engagement (moins de likes, retweets, etc.), mais cette tendance avait déjà commencé avant le rachat de Twitter.
La veille sur les réseaux sociaux est donc aujourd’hui multiple. Mais quels sont les réseaux à envisager pour sa veille ?
Déjà abonné ? Connectez-vous...
Le Text to Mindmap dépoussière les cartes mentales

Alors que l’utilité des cartes mentales est relancée par le renouveau actuel du Personal Knowledge Management, une nouvelle génération, issue des IA génératives, arrive sur le marché.
Ces cartes mentales générées par IA, ou Text to Mindmap, créent instantanément une carte mentale à partir d’un simple titre. Elles constituent un bon exemple de l’apport possible des IA génératives dans les pratiques de veille, quand celles-ci sont utilisées à bon escient.
Utilisés en phase de mise en place et de définition du périmètre d’une recherche ou d’une veille, les outils Text to Mindmap se révèlent ainsi un atout non négligeable. Bien sûr, ils ne sont pas parfaits et ne font pas (tout) le travail, mais ils constituent une première étape intéressante et sans doute un gain de temps et d’attention réels.
À noter : la plupart proposent une option avec ou sans IA, et se présentent avant tout comme des outils de gestion des connaissances.
Emberly organise vos notes
Emberly combine la cartographie mentale et la gestion des notes : ici, les nœuds de la carte servent à stocker des ressources (notes ou liens) (voir figure 1). L’objectif final n’est donc pas de créer une carte mentale, mais bien d’organiser ses pensées et les ressources qui l’alimente. L’utilisation est très simple : après s’être connecté (via son compte Google ou son email), on choisit entre deux options :
- un modèle de carte avec IA ;
- un modèle de carte sans IA.
Dans le premier cas, une fenêtre s’ouvre pour indiquer son sujet, et génère instantanément une carte. Un seul niveau est généré, car il ne s’agit pas d’ajouter un niveau comme dans une carte mentale classique, mais de stocker ici ses ressources, pour les visualiser dans une autre fenêtre qui s’ouvre à droite de la carte. Après la création de chaque branche par l’IA, il est donc possible de les modifier et de stocker chaque ressource dans cette fenêtre de droite. La version gratuite ne permet pas l’upload de fichier.
Une autre fonctionnalité permise par l’introduction de l’IA : l’assistant d’écriture, un chatbot nommé Advisor. Accessible en version gratuite, il peut générer des listes à coller ensuite manuellement dans sa carte mentale. Attention toutefois aux hallucinations de l’IA, on pensera donc à revérifier et à modifier si nécessaire !
Dans le second cas, notre avatar apparaît par défaut au centre de la carte mentale. Le fait que l’avatar soit mis au centre de la carte par défaut rappelle l’objectif initial de l’outil : organiser NOS pensées. Mais si l’on préfère le remplacer par un sujet thématique, on coche le bouton « Use text as center mode » dans les paramètres de la carte.
Nota bene : il n’y a pas d’export de la mindmap en format image dans la version gratuite. Chaque carte, avec ou sans IA, est exportée sous forme de dossier zippé, où chaque branche est un fichier texte. C’est donc ici la fonctionnalité de stockage qui prime sur l’apparence de la mindmap.
Déjà abonné ? Connectez-vous...
Comment utiliser Discord pour ses veilles et ses recherches ?

Avec la multiplication des médias sociaux et les changements récents au sein de X (ex-Twitter) qui conduisent à se poser sérieusement la question d’une alternative, les professionnels de la veille sont amenés à tester, maintenant plus que jamais, de nouveaux canaux pour surveiller (et diffuser) leurs informations.
L’une des plateformes où trouver de l’information de qualité, souvent de niche, est Discord. L’outil étant réservé au départ aux gamers et peu intuitif au premier abord dans une démarche de veille, beaucoup de professionnels n’ont sans doute pas encore osé franchir le pas. Pourtant, la qualité des communautés, du contenu et des relations entretenues sur cette plateforme, ainsi qu’une expérience plus saine pour notre santé mentale, garantie sans intrusion publicitaire ni surcharge algorithmique, valent la peine de fournir un effort supplémentaire. Mode d’emploi.
1) La première approche que l’on peut avoir de l’outil sur la page d’accueil de son site internet, avec ses avatars enfantins aux couleurs pétillantes, et ses catégories de contenu tournées vers les loisirs, est certes déconcertante.
Si les communautés se sont diversifiées, l’outil est toutefois resté fidèle à celles de départ. Mais que l’on ne s’y trompe pas, on retrouvera ici, noyées dans les communautés de jeux, celles de ses outils de recherche et de veille, comme Flint Media, Kagi Search, Inoreader, Video Highlight, Midjourney, mais aussi des cercles VIP de marques de luxe comme Prada, des communautés de journalistes avec Écran Mobile, ou les principales communautés OSINT comme Bellingcat, OZINT ou OSINT-Fr.
Faire partie de la communauté d’un outil, c’est accéder en temps réel aux remontées de bugs et solutions. Par exemple, quand X (ex-Twitter) a cessé de donner l’accès à son API à des tiers, c’est là que les utilisateurs d’Inoreader chattaient avec Inoreader pour identifier des solutions possibles. On retrouve la même chose aujourd’hui avec Midjourney, par exemple, dont le serveur est public.
C’est ici que l’on peut suivre les tutoriels de Bellingcat ou l’actualité d’un outil de veille en temps réel, par exemple. Ou encore la curation des professionnels, tous secteurs confondus. Et il est finalement assez simple de s’y repérer quand on a les clefs. Les voici.
Déjà abonné ? Connectez-vous...
Accès libre aux publications de 655 universités américaines

Les universités américaines publient de grandes quantités de journaux et disposent également d’« entrepôts de données » bien garnis, mais ces informations ne sont pas facilement accessibles et il est exclu de les rechercher sur chaque site d’université.
Ce ne sont pas, en général, des articles « validés par les pairs » tels que ceux dont on trouve les références dans beaucoup de banques de données classiques. Mais ils ne sont pas, pour autant, sans intérêt, car on peut difficilement croire que ces publications sont des « revues prédatrices ».
Nous avons dans ce cadre identifié une source originale et peu connue, qui offre l’accès à des données produites par 655 universités grâce au Digital Commons Network.
Un contenu gratuit
On y trouve plus de 4,5 millions de documents en libre accès : articles, thèses et différents types d’ouvrages.
Il faut savoir que cela ne représente qu’une petite partie des informations publiées par les universités américaines dans leur ensemble, car elles sont plus de 4 000.
● Tous les documents auxquels on a accès sont disponibles gratuitement en texte intégral, le plus souvent en PDF, mais, dans quelques cas, il n’y a pas d’abstract.
● Outre le contenu essentiellement d’origine américaine, on trouve aussi un petit nombre de documents provenant d’universités non américaines situées en Colombie (documents en langue espagnole), en Irlande, en Australie ou à Singapour.
● On remarquera que, pour une fois, le contenu n’est pas quasi uniquement scientifique puisque les sciences humaines et sociales sont très fortement représentées.
Une grande roue pour sélectionner son domaine de recherche
Une des originalités de ce site est la possibilité de définir avec beaucoup de précision son domaine de recherche.
En effet, on dispose, à la connexion à partir d’un PC - mais pas à partir d’un téléphone/smartphone - d’une grande roue dans laquelle figure, sur trois niveaux, l’essentiel des thématiques académiques (voir Figure 1).
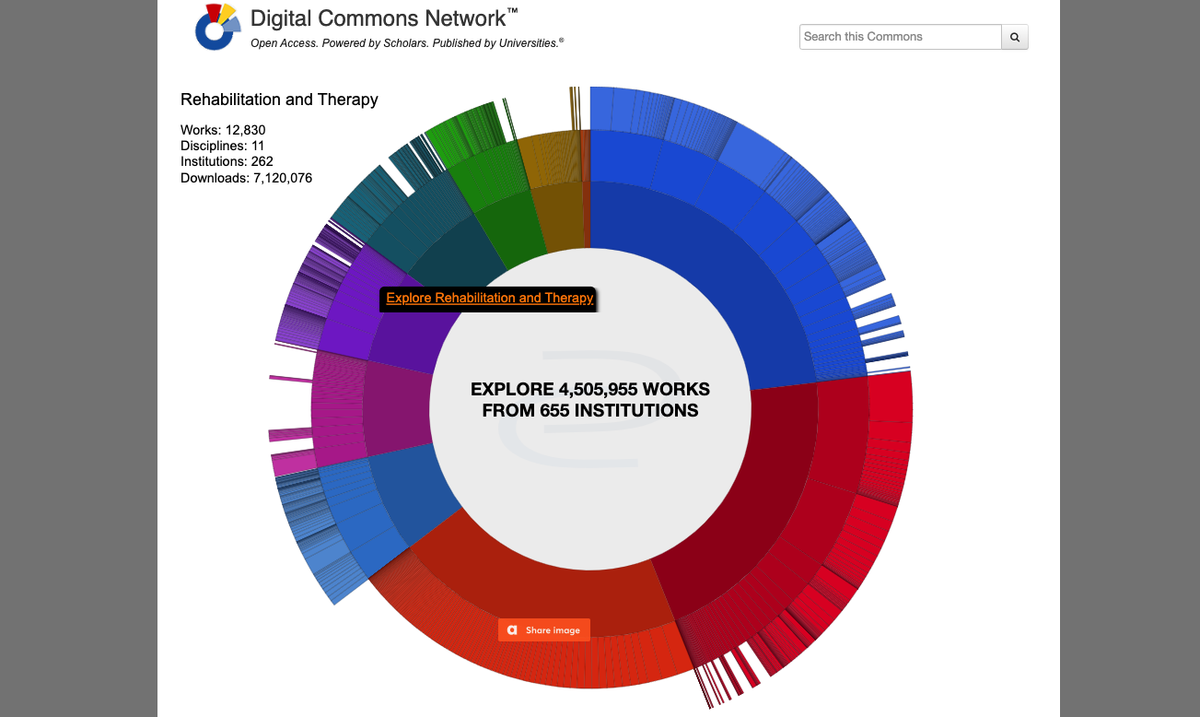
Figure 1 : La page d’accueil du Digital Commons Network présente les recherches sous forme de grande roue.
- ● Le premier niveau, le plus près du centre, présente dix disciplines : droit, sciences sociales et du comportement, art et sciences humaines, sciences de la vie, sciences physiques et mathématiques, éducation, sciences de l’ingénieur, médecine et sciences de la vie, business et, enfin, architecture.
- ● Le deuxième niveau représente des sous-disciplines sur lesquelles on peut cliquer. Par exemple, pour la discipline art et sciences humaines, on trouve histoire, religion, musique, écriture créative, etc., et pour la discipline sciences de l’ingénieur on trouve nanosciences et nanotechnologies, bioressources et ingénierie agricole, science des matériaux, informatique (computer engineering), etc.
Déjà abonné ? Connectez-vous...
Intelligence artificielle : la veille dans un monde sans sources

La fiabilité des sources est un critère essentiel pour les professionnels de la veille. En effet, ils doivent s’assurer que les informations qu’ils collectent sont exactes et fiables afin de pouvoir les transmettre à leurs clients.
Pour cela, ils vérifient davantage la fiabilité des sources en amont en bâtissant un dispositif solide, plutôt que via un «fact-checking après coup» des sources des informations. Cette opération serait en effet bien trop chronophage, le temps devant être consacré à la validation et l’analyse du contenu de l’information lui-même.
C’est ainsi que pour les zones géographiques que l’on maîtrise, on a son échelle de valeur de qualité des sources. Sur des zones que l’on connaît mal, c’est plus difficile.
Aujourd’hui, devant l’impact des IA génératives sur la chaîne de l’information et par souci d’exhaustivité, le veilleur n’a d’autre choix que d’explorer les solutions alimentées à l’IA. Il s’expose ainsi à une masse de contenu non fiable, en provenance des générateurs de texte comme ChatGPT ou Bard, ainsi que des moteurs de recherche dopés à l’IA comme Bing Chat ou Perplexity.
Pour en évaluer le contenu, ces textes générés par IA, dits « synthétiques », doivent être a minima vérifiables. Pour cela, trois éléments sont à vérifier : la source, les faits et leur interprétation. Or, non seulement l’IA génère de fausses informations, mais elle ne permet pas actuellement de les vérifier. Ce faisant, elle va jusqu’à inverser le rapport au temps du veilleur entre la production d’une analyse (qui devient très rapide) et sa vérification (chronophage).
La nouvelle donne : l’invisibilisation des sources par l’IA générative
Tout d’abord, que deviennent les sources à l’heure de l’IA et comment sont-elles traitées par l’IA ?
Traditionnellement, les sources apparaissent sous forme de liens enrichis de snippets - avec des informations complémentaires - dans les moteurs de recherche. Et la recherche entre différentes sources permet de dresser sa propre analyse. Avec l’IA, c’est cette dernière qui fait la recherche à la place de l’utilisateur et lui fournit une réponse. Dans l’absolu, ce n’est donc pas un outil de recherche.
Pour répondre à une question posée, les IA génératives actuelles donnent une réponse sur un ton assertif, mais qui n’est pas vérifiable, là où un moteur de recherche traditionnel ne donne pas de réponse claire, mais plein de sources pour se faire son propre avis.
Lorsque l’on demande une information à ChatGPT, Bard ou aux moteurs de recherche IA, la réponse est instantanée et se suffit à elle-même. Qu’il s’agisse d’une analyse, d’un résumé ou d’une simple requête pratique, les sources s’invisibilisent : les liens sont absents, peu visibles ou même incohérents.
Du côté des générateurs de texte, ChatGPT ne cite pas ses sources (Cf. Figure 1.) et Bard se contente de proposer des recherches complémentaires sur Google, sous forme de boutons. Il y a au moins deux raisons à cette invisibilité :
- Les références sont interprétées comme gênantes pour la fluidité de la lecture ;
- Les IA génératives procèdent à une nouvelle forme de sélection de l’information, probabiliste et non déterministe. Le choix d’une information donnée est fonction d’un critère de probabilité et non comme c’est le cas traditionnellement, déterminés par des événements antérieurs. De plus, ces dernières sont programmées non pas pour dire la vérité (elles n’ont pas cette notion), mais pour être persuasives à notre regard.
Déjà abonné ? Connectez-vous...
FOCUS IA : notre sélection d’outils pour créer des livrables audio

Parmi les outils IA, ceux qui proposent la fonctionnalité de Text-to-Speech (ou Text to Voice) représentent un gain de productivité. On les utilise pour écouter ses sources, ou pour faire écouter son livrable en format audio.
Nous en avons sélectionné quatre, en accès gratuit ou freemium, parmi une vingtaine d’outils explorés.
Nous les avons choisis pour la qualité du son généré par IA, c’est-à-dire le plus proche possible de la voix humaine, et pour la richesse de ce qu’ils offrent déjà dans leur version gratuite.
ElevenLabs, le plus reconnu (freemium)
ElevenLabs est sans conteste celui qui produit la meilleure qualité de voix pour générer un livrable en contenu audio dans plusieurs langues.
C’est aussi le plus généreux dans sa version gratuite puisqu’il offre 10 000 signes/mois à lire (c’est la longueur moyenne d’un article de NETSOURCES), par extraits de 2500 signes maximum (espaces compris), que l’on peut télécharger au format MP3. Ce qui permet un usage régulier.
Surtout, dans la version gratuite, on peut :
- Choisir une voix de synthèse (Speech Synthesis) en version multilingue (huit langues) pour éviter l’accent américain d’un texte français, mais les chiffres sont parfois lus en anglais (même avec un texte français !) ;
- Composer une voix de synthèse dans le VoiceLab (on choisit le genre, le niveau d’accent, et même l’âge !) ;
- Accéder à la « bibliothèque », une nouvelle fonctionnalité avec des voix créées par les utilisateurs. La bibliothèque est intéressante car souvent ces outils sont alimentés par la même API, si bien qu’ils proposent le même catalogue de voix (on les reconnaît car elles ont le même nom sur différents outils !) ...
Déjà abonné ? Connectez-vous...
Europe PMC, une banque de données augmentée en sciences de la vie

Il existe de très nombreuses banques de données bibliographiques de littérature scientifique. Selon les cas, les possibilités de recherche sont plutôt rustiques ou, au contraire, plus ou moins sophistiquées (indexation, opérateurs de proximité, troncatures, conversion des orthographes américaine et anglaises, reconnaissance des abréviations, recherche sur des valeurs numériques, liens citants/cités, recherche par structures chimiques, recherche dans plusieurs banques de données à la fois…).
Europe PMC va plus loin même si elle n’offre pas toutes ces possibilités et nous n’hésitons pas à la qualifier de banque de données augmentée car elle permet, d’une part, de focaliser la recherche sur certaines parties d’un article, par exemple les éléments de méthodologie ou les figures. Elle permet aussi, ce qui est original, d’établir, à partir du contenu d’une référence des liens avec plusieurs banques de données externes plutôt factuelles/numériques, spécialisées dans le domaine des sciences de la vie telles que ChEMBL-small molecules ou MGnify-Metagenomics.
Analyse et évaluation du contenu
Commençons par le contenu, totalement en open access qui est très diversifié tout en restant centré sur les sciences de la vie.
Europe PMC présente, d’une part, ses contenus d’une façon globale, chiffres régulièrement mis à jour :
- 42,7 millions de références dont 35,9 millions venant de PubMed/Medline comme le nom de cette banque de données le laisse entendre. A noter que 70% d'entre elles ont un abstract ;
- 9 millions d’articles en texte intégral ;
- 0,92 millions de références de documents issues de la banque de données Agricola (qui en offre 8,3 millions). Les références les plus récentes apparaissent comme étant publiées en … 2 122. Vérification faite sur le site web, il s’agit bien de 2 023. La plus ancienne date de 1 885 ;
- 4,2 millions de brevets provenant de la banque de données Espacenet de l’OEB (qui en propose 140 millions en tout) ;
- 2 262 NHS guidelines qui sont des « evidence reviews ». Elles sont produites par le plus important organisme de santé au Royaume-Uni. On y accède spécifiquement de la façon suivante, qui est loin d’être intuitive (Cf. Figure 1.) : dans la boite de la recherche simple il faut entrer
PUBLISHER:"nice" OR PUBLISHER:"national institute for health and clinical excellence" OR PUBLISHER:"national institute for health and care excellence" - 628 045 preprints qui proviennent de 31 serveurs de preprints parmi lesquels arXiv, agriRixv, Beilstein archives, bioRxiv, preprints.org, F100 research.
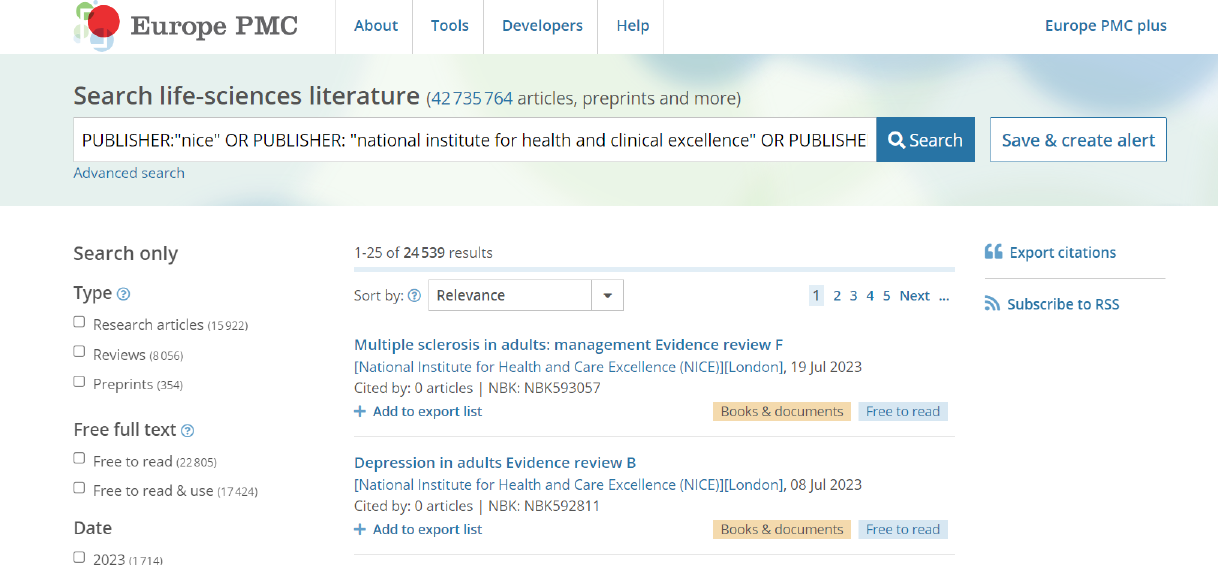
Figure 1. Interface de Europe PMC
La deuxième façon de présenter le contenu est aussi plus opérationnelle puisqu’elle permet de sélectionner une ou plusieurs source(s) parmi celles présentées dans une liste.
Déjà abonné ? Connectez-vous...
La question des références communes à Medline et Embase sur Dialog

Sur Dialog, nous effectuons en général, pour commencer, une recherche sur l’ensemble des banques de données disponibles et, dans un deuxième temps, sélectionnons, au vu des résultats, les banques de données dans lesquelles nous allons poursuivre la recherche.
Voilà un moment que, sur Dialog, nous avions remarqué qu’il arrivait souvent qu’une référence d’Embase (coût 13,24 $) apparaisse alors que la référence au même document dans Medline (coût 3,29 $) était également disponible sur le serveur.
Bien sûr, ces deux bases de données ne sont pas identiques, mais les références communes sont nombreuses et si les abstracts semblent identiques pour ces références communes, les indexations sophistiquées sont propres à chaque base.
Nous avons enfin fini, grâce au service assistance, par comprendre le mécanisme et pouvoir choisir d’obtenir la référence issue de Medline plutôt que celle issue d’Embase.
Dans nos paramètres de recherche (à droite de l’écran), l’option « supprimer les doublons » est activée en permanence, ce qui semble logique, le système choisit alors la référence qui est entrée la première dans Dialog, alors que nous pensions que le choix se faisait en respectant « l’ordre des bases de données préférées » qui figure également à la droite de l’écran. Nous avions préalablement défini cet ordre en mettant en première position « Publicly available content » qui est gratuite et, juste après Medline, Embase arrivant plus loin.
Déjà abonné ? Connectez-vous...
Questel intègre de plus en plus d’IA

Cela fait plusieurs années que Questel n’avait pas organisé physiquement une réunion d’utilisateurs comme c’était le cas auparavant, ce qui a fait que celle organisée récemment a été fort bien accueillie.
Questel au rythme des acquisitions
Pendant ce temps, la vie ne s’est pas pour autant arrêtée pour Questel, qui a continué ses acquisitions de sociétés dans le domaine de la propriété intellectuelle, 18 en cinq ans, portant le groupe à un effectif de 1 700 salariés.
Ces acquisitions ont conduit Questel à ne plus être juste un fournisseur de logiciel mais une plateforme de gestion de la propriété intellectuelle au service de tous types de professionnels de la propriété intellectuelle. Questel définit maintenant sa mission de la façon suivante : « répondre à tous les besoins au long du cycle de vie des titres de propriété intellectuelle ». Cela se traduit par une proposition d’externalisation de la plupart des actes administratifs dans la gestion d’un portefeuille de brevets, en liaison avec le conseil en propriété intellectuelle ou l’expert interne.
Ces actes administratifs concernent en particulier la gestion des paiements des annuités, les entrées en phase nationale des PCT, les traductions, etc.
Questel propose pour cela aux grandes entreprises la plateforme EQUINOX qui est un système d’IPMS (Intellectual Property Management System) développé par la société anglaise du même nom dans laquelle Questel a pris une participation majoritaire en 2022.
De plus en plus d’intelligence artificielle
L’autre point que l’on retiendra de cette journée est le développement de l’utilisation de l’intelligence artificielle dans l’offre Questel. Nous avons échangé à ce sujet à l’issue de la réunion avec Benoit Chevalier qui est Customer Success & Marketing Director.
Déjà abonné ? Connectez-vous...




















