Dans ce numéro, nous publions la première partie d’un dossier complet consacré au prompt engineering. La seconde partie paraîtra dans le prochain numéro de NETSOURCES
Ce dossier a pour objectif de vous accompagner dans la maîtrise du prompt engineering, discipline clé pour exploiter pleinement le potentiel des modèles de langage.
De la compréhension des mécanismes fondamentaux aux techniques les plus avancées, , ces deux articles constituent un guide complet pour maîtriser l’art du prompt engineering et tirer le meilleur parti des modèles de langage actuels et futurs.
Premier article : les fondamentaux du prompt engineering
Ce premier article récapitule les principes essentiels pour optimiser la formulation des prompts:
- Mécanismes internes des LLM : Rappel des processus clés - tokenisation (découpage du texte), embeddings vectoriels (représentation numérique) et architecture transformer (mécanismes d’attention) - pour comprendre comment les modèles traitent les prompts).
- Frameworks de structuration : Présentation de méthodologies structurantes combinant contexte, rôle et format de sortie, illustrées par des exemples concrets d’application.
- Techniques avancées : Exploration de méthodes sophistiquées comme les chaînes de pensées, ainsi que des techniques parfois méconnues comme l’utilisation de délimiteurs.
- Stratégie de longueur : Faut-il privilégier un prompt long et complet («méga-prompt») ou procéder par itérations successives ? La longueur optimale du prompt est une question cruciale.
Tous nos articles
Wikipédia et Grokipedia : la bataille du savoir à l’ère de l’IA
Anne-Marie LIBMANN
Créé le
mercredi 22 octobre 2025
1966


À l’heure où l’intelligence artificielle redéfinit l’accès au savoir, Wikipédia et Grokipedia, le nouveau projet d’Elon Musk, incarnent deux visions opposées : l’une communautaire et ouverte, l’autre centralisée et portée par xAI. Alors que Wikipédia adapte ses données pour dialoguer avec les IA tout en préservant sa transparence, Grokipedia promet une alternative « sans biais ».
Le Wikidata Embedding Project : Wikipédia s’adapte à l’IA
Lancé le 1ᵉʳ octobre 2025 par la Wikimedia Foundation, en partenariat avec Jina.AI et DataStax, le Wikidata Embedding Project vise à rendre les 119 millions d’entrées de Wikidata, alimentées par 24 000 contributeurs actifs, exploitables par les intelligences artificielles.
Grâce à la recherche vectorielle, qui traduit les concepts en relations numériques via des modèles comme Jina Embeddings v3 (multilingue, jusqu’à 8 192 tokens), le système dépasse les recherches par mots-clés. Une requête sur « scientifique », comme l’illustre le site TechCrunch, proposera ainsi des biographies comme celles de Marie Curie ou Albert Einstein, des concepts liés comme la méthode scientifique ou des visuels tels que des schémas de formules.
Ce projet s’appuie sur des APIs vectorielles ouvertes, notamment celles de DataStax (Astra DB), pour intégrer les données de Wikidata dans les assistants IA via la technologie RAG (Retrieval Augmented Generation). Un webinar le 9 octobre 2025 a marqué le lancement, avec un support initial en anglais, français et arabe, et 30 millions d’entrées déjà vectorisées.
Maryana Iskander, PDG de la Wikimedia Foundation : "Face à l’IA, nous devons préserver notre modèle ouvert en l’intégrant intelligemment."
Cette stratégie répond à une urgence : les résumés IA de Google, déployés à grande échelle en 2025, captent 8 % du trafic humain de Wikipédia, menaçant ses dons, qui représentent 80 % de son financement.
Comment s’assurer d’une review positive, voire très positive ?
François LIBMANN
Bases no
439
Créé le
jeudi 9 octobre 2025
2566


On n’est jamais si bien servi que par soi-même…, c’est la conclusion que l’on peut tirer de la lecture du récent article du NIKKEIAsia « Invisible prompts in manuscripts: Authors use AI ‘prompt injection’ to sway peer review ».
Les auteurs de l’article de NIKKEIAsia ont découvert que de petits malins, auteurs ou co-auteurs de 17 articles, en attente de review, présents dans arXiv - le bien connu et plus ancien réservoir de preprints - ont trouvé un moyen de « forcer » une IA à donner une excellente évaluation de leur article.
L’objectif de la manipulation : permettre ou au moins faciliter la publication de l’article dans un journal de bonne réputation ou l’acceptation d’une soumission d’une conférence à un congrès.
Comment s’y sont-ils pris ?
De la RPA à l’IA générative : le parcours du service info de Deloitte France vers une gestion intelligente de l’information
Christel RONSIN
Bases no
439
Créé le
jeudi 9 octobre 2025
2563

Interview de Sylvie Sage, responsable du service d’information de Deloitte France. Interview menée par Christel RONSIN
Nous avons souhaité interroger Sylvie Sage afin de recueillir son témoignage sur la mise en place et l’utilisation de l’intelligence artificielle générative au sein d’un grand cabinet de conseil.
Sylvie Sage est responsable du Business Research Center (BRC) de Deloitte France depuis 17 ans. Elle est également impliquée au sein du Groupement Français de l’Industrie de l’Information (GFII) depuis 8 ans. Elle est co-animatrice du groupe de travail « Sourcing et analyse de l’information stratégique » du GFII.
CHRISTEL RONSIN : Sylvie, pouvez-vous nous expliquer dans quel contexte l’utilisation de l’intelligence artificielle générative est apparue au Business Research Center de Deloitte France ?
Stratégie et innovation : LexisNexis® transforme-t-il l’analyse brevet ?
Philippe BORNE
Bases no
439
Créé le
jeudi 9 octobre 2025
2465
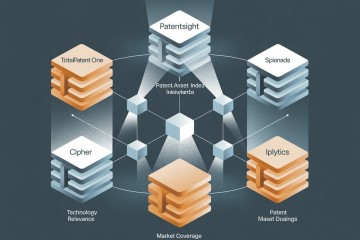
LexisNexis® est arrivé tard sur le terrain des bases de données brevet accessibles en ligne, à l’automne 2007 très exactement, avec le service TotalPatent®, devenu aujourd’hui TotalPatent One®, soit 30 ans après des acteurs comme Derwent™ - la base Derwent World Patents Index® (DWPI) a été mise en accès sur le serveur américain Orbit® en 1976 et plus tard sur Dialog® et Questel®.
Suivant un processus d’acquisitions successives déjà mis en œuvre avec un certain succès par Questel®, l’offre de LexisNexis® dans le domaine s’est enrichie au cours des cinq dernières années avec l’intégration de trois outils au caractère assez inhabituel et même disruptif : PatentSight®, Cipher® et IPLytics®. Ce nouveau trio mérite un examen que nous nous proposons ici de réaliser.
Nous mènerons cet examen en deux temps : dans cette première partie nous décrirons les métriques qui permettent à PatentSight d’attribuer une valeur à un brevet et dans une deuxième partie - qui sera publiée dans le prochain numéro de BASES, nous donnerons des exemples concrets pour répondre à des problématiques précises en matière de stratégie de propriété industrielle : estimation de la valeur de mon portefeuille, analyse de mon positionnement et détection d’opportunités entre autres.
ChatGPT Pulse : l’IA proactive au service de la veille personnalisée
Anne-Marie LIBMANN
Bases no
439
Créé le
jeudi 9 octobre 2025
2377

Pulse innove dans le domaine de la veille proactive, à la croisée de l’assistance conversationnelle et de l’automatisation intelligente.
Là où des modèles comme Claude (Anthropic) ou Gemini (Google) excellent dans le raisonnement contextuel à la demande, Pulse adopte une logique anticipative : il ne se contente pas de répondre, il anticipe les besoins.
Dans l’écosystème des agents intelligents, Zapier Agents et ChatGPT Deep Research explorent des voies complémentaires - l’un dans l’automatisation de tâches, l’autre dans la recherche approfondie sur requête. Mais aucun ne propose encore la régularité, la contextualisation et la pertinence personnelle que Pulse place au cœur de son expérience.
Avec Instant Checkout, OpenAI fait entrer l’IA entre dans l’ère du commerce transactionnel
Anne-Marie LIBMANN
Bases no
439
Créé le
jeudi 9 octobre 2025
2350

Le 29 septembre 2025, OpenAI a lancé aux États-Unis Instant Checkout, et transforme ChatGPT en véritable plateforme d’achat intégrée.
L’utilisateur peut désormais formuler une requête pour un produit, explorer les recommandations de l’IA, puis finaliser son achat sans quitter la conversation.
Présentée comme une simplification radicale de l’expérience client, cette nouveauté marque un tournant majeur : l’IA ne se limite plus à assister, elle agit et conclut la transaction.
Ce changement ouvre la voie à une nouvelle forme de commerce en ligne, tout en soulevant des questions cruciales de gouvernance des données et de transparence algorithmique.
De la requête à l’achat, une expérience sans rupture
Jusqu’en 2024, ChatGPT se bornait à suggérer des produits et à rediriger vers des liens externes.
Comment accéder à 4 millions de thèses européennes en 2025 (sans perdre des heures)
Rédaction
Créé le
mercredi 1 octobre 2025
4544

DART-Europe a fermé. EThOS est hors service. Global ETD Search de NDLTD est indisponible.
Trois piliers de l’accès aux thèses européennes ont disparu… mais la recherche continue.
Le nouveau Guide des thèses européennes 2025, conçu par l’équipe de BASES (votre référence en information spécialisée depuis 1985), devient l’outil incontournable pour accéder à plus de 4 millions de thèses à travers 25 pays.
Un contexte bouleversé
- Février 2025 : fermeture définitive de DART-Europe (1 million de thèses, 29 pays).
- Depuis 2023 : EThOS (Royaume-Uni) hors service après cyberattaque.
- Depuis des mois : Global ETD Search (NDLTD) indisponible.
👉 Résultat : les chercheurs et documentalistes se retrouvent sans passerelle centralisée pour accéder aux thèses européennes.
Maîtriser l’IA, un art au service de l’intelligence humaine
Anne-Marie LIBMANN
Netsources no
177
Créé le
mardi 16 septembre 2025
2505

L’intelligence artificielle générative n’est pas qu’un outil de productivité : elle redéfinit notre manière de penser, de créer et d’interagir avec l’information. Elle peut devenir une alliée puissante, à condition de l’aborder comme un levier d’amplification de l’intelligence humaine plutôt qu’un substitut.
Ce nouveau numéro de Netsources explore cette ambition à travers quatre dimensions : la maîtrise du dialogue avec le modèle IA, l’évaluation critique des innovations, la création multimédia et plus essentielle que jamais, la préservation de nos capacités intellectuelles.
D’abord, l’art du dialogue avec l’IA. Véronique Mesguich (« Le prompt, un art pour la veille stratégique et la recherche d’information »), montre que le prompt engineering dépasse la simple formulation technique : c’est une discipline de précision, qui fait du professionnel un véritable architecte de requêtes, capables d’augmenter significativement la performance des résultats générés par les LLM.
La mise à l’épreuve des outils illustre cette exigence. Dans son analyse (« ChatGPT Agent : un collaborateur virtuel pour les professionnels de l’information ? »), Ulysse Rajim teste l’agent autonome d’OpenAI sur des tâches comme l’analyse concurrentielle, l’audit SEO ou le social listening. Impressionnant par sa rapidité, l’outil révèle aussi ses limites : erreurs factuelles, accès bloqué par des paywalls, incertitudes liées à la confidentialité des données.
Le prompt, un art pour la veille stratégique et la recherche d’information (1ere partie)
Véronique MESGUICH
Netsources no
177
Créé le
mardi 16 septembre 2025
3789

Test complet de ChatGPT Agent : que vaut-il pour la veille, l'analyse concurrentielle et l'audit SEO ?
Ulysse RAJIM
Netsources no
177
Créé le
mardi 16 septembre 2025
3700

ChatGPT Agent promet de révolutionner l'automatisation des tâches professionnelles. Recherche intelligente, navigation autonome, exécution complète de missions complexes : marketing ou réalité ? Nous avons testé l'outil en conditions réelles sur trois métiers critiques de l'information. Notre verdict sans concession.
Avec le lancement de sa nouvelle fonctionnalité Agent, OpenAI enrichit ChatGPT de nouvelles capacités. En plus des échanges conversationnels, l’outil peut désormais exécuter des tâches complexes en combinant recherche avancée et actions autonomes dans un navigateur. C’est en tout cas la promesse : fusionner les capacités d’analyse de Deep Research et d’action d’Operator pour créer un assistant capable de prendre en charge une tâche de A à Z.
Pour évaluer les capacités réelles de cet agent dans un contexte professionnel, nous l’avons mis à l’épreuve à travers trois cas d’usage concrets : une analyse concurrentielle, un audit SEO et une étude de social listening.
I. Présentation de ChatGPT Agent
Annoncée le 17 juillet 2025, la fonctionnalité Agent de ChatGPT est disponible en France depuis le 8 août pour les abonnés aux forfaits Plus, Pro et Team. Elle est issue de la fusion de deux technologies qu’OpenAI développait en parallèle : d’une part, Deep Research, un système de recherche approfondie capable de parcourir des centaines de sources pour synthétiser des sujets complexes, et d’autre part, Operator, un agent capable de prendre le contrôle d’un navigateur web pour effectuer des actions comme cliquer sur des liens ou remplir des formulaires. En combinant les deux, ChatGPT Agent vise à permettre de déléguer à l’IA des activités plus complexes.


