Brandwatch : une plateforme de veille qui allie puissance et flexibilité


Brandwatch est un acteur britannique spécialisé dans la veille et l’analyse sur les médias sociaux.
La société a été fondée en 2005 à Brighton mais la plateforme de veille Brandwatch Analytics a été lancée en 2007.
Depuis, l’entreprise s’est considérablement agrandie avec des bureaux à New-York, San Francisco, Berlin, Stuttgart, Singapour et, depuis peu, Paris, même si l’entreprise était déjà présente sur le marché français depuis quelques années avec des équipes francophones réparties entre Paris et Brighton.
Brandwatch propose trois produits distincts mais compatibles :
- Brandwatch Analytics une plateforme de veille sur les médias sociaux et d’analyse ;
- Brandwatch Vizia : une solution de surveillance des médias sociaux avec représentation des données en temps réel (utile par exemple dans le cadre de la surveillance des retombées d’un événement) ;
- Audiences : une base de données d’influenceurs qui compte plus de 300 millions de comptes Twitter.
Nous avons testé la plateforme Brandwatch Analytics et c’est à ce produit que nous allons consacrer cet article.
Brandwatch Analytics en bref
La plateforme surveille et indexe plus de 90 millions de sources en ligne.
Comme dans la très grande majorité des outils de veille, l’intégralité des sources surveillées sont des sources gratuites.
On y trouve :
- des sites d’actualités/presse en ligne, dans le monde entier
- des blogs (plusieurs millions),
- des forums (plusieurs centaines de milliers),
- des réseaux sociaux (Facebook, Twitter, Vkontakte, RenRen, Sina Weibo, Tencent Weibo, Taringa, Reddit, Digg, Xing, etc.).
- des vidéos (Dailymotion, YouTube, Vimeo),
- des images (Instagram notamment),
- des plateformes d’avis (Tripadvisor, CNET, etc.).
44 langues sont prises en compte dont le français, l’anglais ou encore le chinois et le russe mais la plateforme a également une fonction de recherche qui permet de travailler avec n’importe quelle langue.
On notera d’ailleurs que Brandwatch est partenaire officiel de Twitter, ce qui lui permet d’offrir l’intégralité des données de Twitter en temps réel mais également d’avoir accès à l’intégralité des archives depuis 2006.
Pour les autres réseaux sociaux, Brandwatch fait preuve de transparence en indiquant qu’il n’est pas possible de les couvrir à 100%, les différents acteurs imposant des restrictions. Pour LinkedIn par exemple, l’outil peut surveiller les blogs et forums d’aide mais pas les groupes ou les profils.
Brandwatch disposait jusqu’à peu d’un partenariat avec Datasift (voir Netsources n°122 - mai/juin 2016) mais y a renoncé. Rappelons que Datasift récupère grâce à un partenariat avec Facebook toutes les données publiées sur ce réseau social. L’objectif : permettre aux marques d’avoir un accès facilité à l’ensemble des données publiées sur Facebook (qu’elles soient publiées sur des comptes privés ou des pages ou groupes publics). Pour des questions de protection de vie privée, ces données sont anonymisées, mais offrent tout de même un accès à près de 65 attributs (sexe, âge, localisation...).
A la place de Datasift, Brandwatch va très probablement se tourner vers la nouvelle API Audience Insights développée et testée par Facebook. Brandwatch considère que cette API sera la seule stratégie de Facebook en ce qui concerne la mise à disposition de ses données.
Des fonctionnalités de recherche puissantes
L’un des points forts de l’outil repose dans sa capacité à créer des requêtes longues, précises et complexes. L’interface de création de requêtes n’est d’ailleurs pas sans rappeler celles d’agrégateurs de presse comme Factiva.

Figure 1. Interface de création de requêtes
On peut utiliser les opérateurs classiques AND, OR et NOT, les guillemets pour la recherche d’expression exacte et les parenthèses pour expliciter l’ordre de la recherche.
Mais les possibilités de recherche vont bien au delà de ce premier niveau avec des opérateurs avancés, finalement pas si éloignés de ce que peuvent proposer les agrégateurs de presse traditionnels :
- NEAR/x : pour retrouver un ou plusieurs termes à x mots maximums d’un autre par exemple :
(apple OR orange) NEAR/5 (smartphone OR phone) - NEAR/xf : pour retrouver un ou plusieurs termes à x mots maximums d’un autre en respectant l’ordre indiqué par exemple :
(prévisions NEAR/5f embauches) - title: pour rechercher dans le titre de la page uniquement
- author: pour rechercher dans le champ auteur quand il est disponible
- la troncature
*pour un nombre de caractères illimités et?pour remplacer un seul caractère - hashtags: pour rechercher spécifiquement des hashtags
- raw: pour respecter la casse d’un mot ou d’une expressionpar exemple :
raw:Totalpour rechercher uniquement le terme avec une majuscule ouNOT raw:RTpour éliminer les mentions contenant RT en majuscules et ainsi éliminer tous les retweets - site: pour délimiter la recherche à un (des) site(s) ou une(des) source(s)
- url: pour rechercher une url précise ou un mot contenu dans une url
- links: pour rechercher les mentions qui pointent vers un site ou une url précise. Fonctionne même quand l’url est raccourcie.
On peut également limiter la recherche à un continent, un pays, un état ou une ville.
Quand l’analyse rime avec la personnalisation
Toutes les plateformes de veille sur les médias sociaux proposent des solutions d’analyse mais on se retrouve souvent vite limité à quelques visualisations et graphiques. Chez Brandwatch, tout est personnalisable.
Une fois ses requêtes (Queries) créées, l’utilisateur va pouvoir visualiser les résultats dans ce que Brandwatch appelle des Dashboards . L’utilisateur peut choisir à partir d’un dashboard vide et d’ajouter les informations et éléments d’analyse qui l’intéressent ; il peut aussi partir de modèles existants (résumé des données importantes, focalisation sur Twitter, Facebook, mise en évidence des tendances, influenceurs, etc.).
Sur le modèle « résumé des données importantes », l’un des plus classiques, on trouve par exemple pour la période choisie :
- le nombre de mentions
- le nombre d’auteurs uniques
- les principaux sujets abordés
- les principales actualités sur le sujet
- des graphiques avec les mentions par jour, heures, etc
- une répartition des mentions par analyse du sentiment
- les sujets les plus abordés sur Twitter (éléments les plus tweetés, utilisateurs les plus actifs, hashtags les plus utilisés)
- évolution des sujets sur une période donnée
- listes et éléments démographiques sur les auteurs (basés sur des techniques complexes de machine learning qui analysent les biographies Twitter)
- graphiques sur la répartition par type de sources
- listes des principales sources d’actualités, forums ou blogs
- l’intégralité des mentions répondant à la requête.
On notera que chaque élément est cliquable et permet donc d’accéder aux mentions brutes d’un seul clic.
On peut également modifier chaque graphique en modifiant les axes (abscisses et ordonnées) du graphique ou bien en modifiant la période de recherche ou bien encore en filtrant le contenu selon différents critères (voir ci-dessous).
Autre point fort de ces dashboards : les nombreuses possibilités de filtres qui s’appliquent à tout le dashboard ou bien à un ou plusieurs éléments uniquement.
On peut ainsi filtrer les résultats par :
- sentiment ou type de résultats (actualités, images, Twitter, etc.) - on peut également exclure certains types de résultats ;
- auteur (nom de l’auteur ou bien limiter ou exclure une liste d’auteurs préalablement créée par l’utilisateur) ;
- éléments relatifs aux forums (nombre de posts au minimum/maximum, nombre de vues au minimum/maximum) ;
- éléments relatifs aux blogs (nombre de commentaires minimum/maximum) ;
- éléments relatifs à Twitter (nombre de retweets, nombre total de tweets, nombre de followers, nombre de personnes suivies, score d’influence, nombre d’impressions, compte vérifié, etc.) ;
- éléments relatifs à Instagram (type de mention, nombre d’interactions, nombre de « likes », nombre de commentaires, nombre de posts, nombre de followers, nombre de personnes suivies) ;
- éléments relatifs aux sites Web (mozrank (score de popularité), nombre de backlinks, limtation ou exclusion d’une liste de sites, nombre de visiteurs par mois, etc.) ;
- localisation (limitation ou exclusion de certains lieux) ;
- par tag ou catégorie (nous en reparlerons par la suite) ou exclusion de certains tags ou catégories.
Mise en pratique
Pour mieux comprendre le fonctionnement de l’outil, nous avons choisi de présenter le processus de mise en place d’une veille et d’analyse sur Brandwatch à travers un exemple concret.
Nous avons ainsi choisi de mettre en place une veille sur un grand acteur de l’électroménager Whirlpool en nous focalisant sur deux aspects distincts : d’une part les usines de Whirlpool avec un intérêt particulier pour certaines usines en Europe et d’autre part tout ce qui concerne plus largement la stratégie du groupe dans le monde entier (nominations, plans sociaux, vision stratégique, résultats financiers, etc.).
Tout débute par la création d’un projet que nous appellerons « Whirlpool ». Une fois le projet créé, l’utilisateur retrouve tous les éléments utiles pour la mise en place dans la colonne de gauche : dashboards, data, tools, reports, alerts.
Data pour la création des requêtes et surveillance
C’est dans l’onglet Data que nous allons créer les requêtes en choisissant l’option queries. Deux possibilités sont alors offertes : Query Wizard, un assistant à la création de requête adapté pout toutes les personnes peu familières des requêtes booléennes complexes et Query Editor, l’interface de création de requêtes booléennes traditionnelles. C’est ce dernier que nous avons choisi d’utiliser.
Nous avons ainsi créé deux requêtes, une pour les usines et une pour la stratégie générale du groupe.
Requête n°1 :
Whirlpool AND (Amiens OR Cassinetta OR Naples OR Napoli OR Proprad OR Sienne OR siena OR Trento OR Wroclaw OR manufacturing OR plant? OR usine* OR (site* NEAR/2 production*))
Requête n°2 :
Whirlpool AND (launch* OR lance* OR partnership* OR collaboration* OR partenariat* OR acquisition* OR agreement* OR acquire* OR purchase* OR rachat* OR rachet* OR innov* OR innovative* OR award* OR r?compense* OR invest* OR investi* OR financial* OR financier* OR nomination* OR appoint* OR nomm* OR announc* OR (job* NEAR/3 cut*) OR licencie* OR restructur*)
On visualise à ce stade les mentions répondant aux critères sur les 8 derniers jours, un graphique sur l’évolution des mentions, les principaux sujets abordés, les sites et auteurs les plus cités sur les 8 derniers jours. Cela permet d’estimer le volume d’information généré ainsi que la pertinence des résultats afin de pouvoir réorienter ci-besoin la requête. Cela peut être particulièrement utile pour les personnes disposant d’un abonnement avec une limite de mentions par mois.
On peut également choisir si l’on souhaite visualiser toutes les mentions répondant à la requête ou bien un panel aléatoire de 1 à 99 %, ce qui pourra limiter et réduire le volume d’informations généré chaque mois.
Toujours dans la rubrique Data, nous avons ensuite créé plusieurs Channels. Ces Channels permettent de mettre sous surveillance tout le contenu d’un compte Twitter public, une page Facebook publique ou un compte Instagram public. Nous avons ainsi mis sous surveillance les comptes Facebook et Twitter de plusieurs entités du groupe Whirlpool.
Nous avons ensuite créé un groupe regroupant la requête n°2 (sur la stratégie du groupe) avec les différentes Channels mises sous surveillance afin de pouvoir les utiliser d’un seul bloc par la suite.
Tools pour raffiner la surveillance
C’est dans la rubrique Tools que l’utilisateur va pouvoir affiner la surveillance et créer un certain nombre de filtres qui lui seront utiles lors de la visualisation des résultats.
Nous avons commencé par créer des listes de sites (Site lists) :
- une liste avec les sites institutionnels de l’entreprise Whirlpool (site du groupe, des différentes entités, blogs de l’entreprise, comptes Twitter, Facebook, etc.),
- une liste des sites, blogs, comptes sur les réseaux sociaux des organisations syndicales de l’entreprise,
- une liste de sources locales (presse locale, compte d’élus locaux, etc.) pour les usines qui nous intéressaient tout particulièrement en France, Italie et Pologne.
Cela nous permettra par la suite de visualiser ou d’exclure les mentions postées par l’entreprise elle-même, de visualiser uniquement en un clic les mentions relatives aux organisations syndicales ou encore de visualiser spécifiquement ce qui se dit sur Whirlpool dans les sources locales des usines qui nous intéressent le plus.
On notera qu’il est aussi possible de créer des location lists (pour limiter ou exclure les mentions provenant d’un ou plusieurs continent, pays, villes) et des authors lists (listes d’auteurs soit des journalistes, comptes Twitter, nom d’utilisateurs de forums, auteurs de blogs, employés etc.).
On peut ensuite créer des Categories et des Tags pour segmenter le contenu identifié par Brandwatch. Les tags sont plus simples à utiliser mais permettent moins d’actions que les catégories. C’est pour cette raison que nous avons choisi d’utiliser les catégories.
Nous en avons créé deux : une pour les usines avec les noms des villes où elles sont implantées et une pour les produits fabriqués par ces usines (lave-vaisselle, four, congélateur, etc.).
On peut ensuite manuellement ajouter ces catégories aux mentions récupérées ou bien créer des règles automatiques (appellées Rules). C’est ce que nous avons fait en indiquant par exemple à l’outil d’ajouter automatiquement la catégorie Usine et la sous-catégorie Amiens dès que le mot Amiens apparaissait dans une mention récupérée par les deux requête n°1 et 2 ou sur les différentes Channels créées. Nous avons créé ainsi une règle différente pour chaque usine.
Nous avons fait de même pour les produits électroménagers en créant par exemple la règle suivante : dès qu’un résultat contient les termes dishwasher* OR (lave? NEAR/2 vaisselle?) dans les requêtes n°1 ou 2 ou les différentes Channels, ajouter la catégorie Produit et la sous-catégorie Dishwasher.
Nous le verrons par la suite mais ces catégories seront très utiles lors de l’analyse et la visualisation des résultats.
Le dashboard pour l’analyse et la visualisation des résultats

Figure 2. Dashboard dédié à la stratégie sur les usines
Nous avons ensuite créé deux dashboards : un relatif aux usines (incluant la requête sur les usines) et un sur la stratégie du groupe (incluant la requête sur la stratégie et les différentes Channels). Nous avons choisi le modèle Summary pour avoir une vision globale des informations mais nous aurions également pu créer un dashboard complètement personnalisé ou utiliser des modèles qui se focalisent sur Twitter, Facebook, Instagram, etc.
Les informations présentées dans les dashboards sont nombreuses et permettent bien de faire ressortir les éléments importants. Dans notre exemple, on constate un pic de mentions le 24 janvier, date à laquelle Whirlpool a annoncé la fermeture de son usine d’Amiens.
On peut également modifier chaque graphique en modifiant les axes du graphique ou bien en modifiant la période de recherche ou encore en filtrant le contenu selon différents critères, par exemple en limitant ou en excluant les listes de sites (sites institutionnels de Whirlpool, organisations syndicales ou sites locaux) que nous avions créés précédemment.
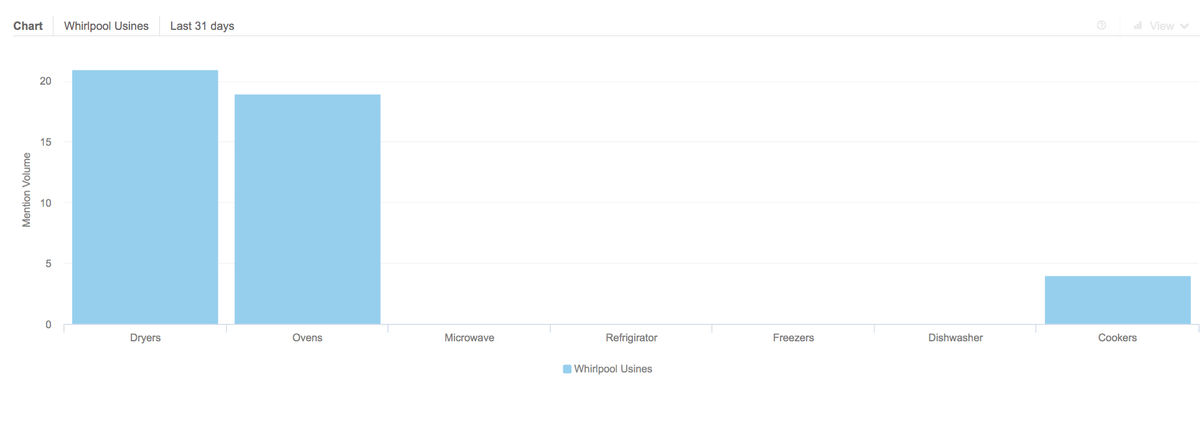
Figure 3. Graphique sur le volume d’informations pour la catégorie « produits » (fours, lave-vaisselle, etc.)
Nous avons ensuite rajouté un onglet en créant plusieurs graphiques pour analyser les contenus que nous avions catégorisés :
- un premier graphique permettant de voir le volume d’information généré sur le dernier mois sur les noms des usines. On constate alors que la majorité des mentions parlent d’Amiens et quelques mentions parlent de l’usine de Lodz mais aucune autre usine n’est mentionnée au cours des 30 derniers jours.
- Le second graphique permet de voir le volume d’informations relatif à chaque produit (lave-vaiselle, four, etc.) au cours des 30 derniers jours. On constate qu’il est surtout question des sèche-linges et des fours et dans une moindre mesure des cuisinières. Un clic sur chaque élément du graphique permet de visualiser instantanément les mentions.
Notons qu’il est aussi possible de croiser les catégories pour voir quel type de produit est le plus mentionné en rapport à quelle usine par exemple.
Reports et Alerts
Nous avons ensuite créé des Reports afin d’avoir un aperçu des résultats au quotidien. Les Reports sont des documents envoyés par mail chaque jour, chaque semaine, chaque mois ou chaque trimestre permettant soit d’avoir une vision globale de nouveautés, soit d’avoir une vision spécifique sur Twitter ou encore de comparer plusieurs requêtes entre elles.
Pour finir, nous avons mis en place des alertes intelligentes appelée Signals sur certaines requêtes et certaines catégories spécifiques afin d’être prévenu lorsque le volume d’information généré est inhabituel ainsi que des Customs Alerts complètement personnalisables pour, par exemple, recevoir une alerte lorsque le terme Amiens apparaît dans une mention mais uniquement sur la liste de sites des organisations syndicales que nous avions créée.
Notons enfin que tout ou partie des données peut être exportée sous différents formats.
Notre avis sur le produit
La couverture de sources proposée par Brandwatch est conforme à ce que l’on peut attendre d’un outil de veille sur les médias sociaux et les sources gratuites du Web. On appréciera d’ailleurs la présence de plusieurs réseaux sociaux locaux (notamment en Chine ou en Russie), ce qui n’est pas systématique pour les outils de veille de ce type.
L’intégration de sources payantes ou du moins l’intégration de données récupérées par l’utilisateur sur des sources payantes pour pouvoir les analyser serait évidemment un plus.
Les fonctionnalités de recherche sont puissantes et parmi les meilleures du marché et mêmes proches de certains agrégateurs de presse comme Factiva, Pressedd, LexisNexis, etc. Brandwatch réussit le pari de proposer un outil moderne de surveillance des médias sociaux tout en mettant en avant la valeur d’une recherche d’information complexe traditionnelle comme les professionnels de l’information l’affectionnent.
Les fonctionnalités d’analyse nous ont également séduits d’une part grâce à la force de la personnalisation mais également grâce à la puissance des filtres et notamment des catégories et tags.
Enfin, la capacité de Brandwatch à proposer des archives est un élément intéressant pour les professionnels de l’information souvent amenés à effectuer des recherches rétrospectives. Et cela s’avère généralement compliqué sur les médias sociaux.
Même si la couverture des archives n’est pas exhaustive, elle est au dessus de ce que peut proposer la concurrence : panel aléatoire de 10% des archives de Twitter depuis 2006 ou accès à l’intégralité des archives de Twitter jusqu’en 2006 (options payantes) et archives des sources indexées par Brandwatch sur les trois dernières années.
Abonnements
Brandwatch propose trois abonnements différents à sa plateforme Brandwatch Analytics : Pro, Enterprise M et Enterprise Q.
Les principales variantes entre ces différents abonnements se situent au niveau du nombre de mentions mensuelles inclus dans l’abonnement (de 10 000 mentions par mois à un nombre illimité) ou du nombre de Queries. Les données historiques permettant de faire des recherches rétrospectives et analyses (elles remontent sur 30 jours pour l’abonnement le moins cher et peuvent remonter sur 3 ans pour l’abonnement le plus cher et même 2006 pour Twitter en service payant additionnel).
Lien : www.brandwatch.com/fr