Maîtriser l'Open Data et l'IA pour transformer et exploiter les données différemment


En France, pays champion européen de l’open data, on parle souvent des startups qui parviennent à exploiter des données accessibles en accès gratuit, pour en faire des services, avec parfois une option payante, à l’instar de Pappers ou Doctrine.
Depuis la démocratisation de l’IA amorcée il y a plus d’un an avec la mise à disposition au public de ChatGPT, suivie depuis par d’autres IA génératives et services afférents, comment le traitement des données ouvertes a-t-il évolué et surtout, est-il davantage accessible à un utilisateur sans formation technique particulière en amont ? Exploration, étape par étape, du traitement des données, de l’extraction à la publication.
Extraction facilitée
Première étape : la collecte des données. Celle-ci peut se faire de deux façons : en téléchargeant un dataset ou en procédant à l’extraction des données sur un document. C’est dans ce second cas que les outils IA interviennent. S’offrent alors deux possibilités d’extraction de données :
- Avec un outil IA où l’on importe un fichier de données.
- Avec un tableur habituel, auquel on ajoute un module IA.
Avec un outil IA
Les outils IA qui permettent d’importer gratuitement des documents à traiter ne prennent pas en charge les formats de bases de données, mais uniquement les formats textes et PDF. Dans ce cas, extraire les données d’un document pour les récupérer sous forme texte ou de tableau est un jeu d’enfant.
Prenons par exemple ce document qui dresse une liste des hôpitaux en France en 2013, trouvé par une requête Google « liste hôpitaux en France PDF ».
- Pour en extraire les hôpitaux d’une région, on a d’abord utilisé DUST, un outil IA français d’analyse de données. Un autre outil existe avec des fonctionnalités similaires, Retune. Le procédé est simplissime : on colle le lien ou on importe le document (formats TXT, PDF et MD (Markdown), de taille inférieure à 10 Mo), on choisit le modèle de langage (GPT 3.5 ou Claude) et on rédige son invite. L’extraction de données ne peut se faire qu’avec Claude et non avec GPT 3.5. Dans ce cas, un simple « Extrais la liste des hôpitaux en Île-de-France » suffit à récupérer une liste sous forme de texte. En revanche, les tentatives pour fournir les résultats sous forme de fichier à télécharger n’ont pas abouti.
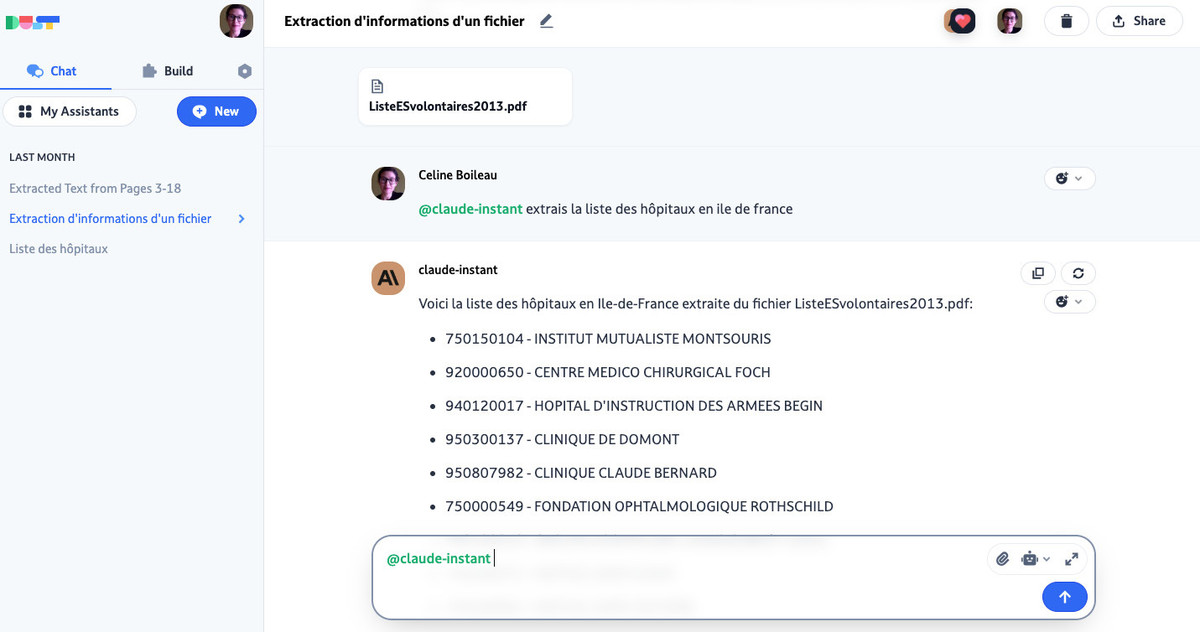
Figure 1 : L’extraction de données ave DUST. Sur simple demande.
- Un autre test avec un PDF de 22 pages, agrémenté de nombreux graphiques, a aussi permis d’extraire le texte, pour ensuite le résumer. Et comme l’invite était en français, Claude s’est exécutée en français, faisant l’économie d’un prompt (ou invite) de traduction.
- Un autre outil, plus connu des veilleurs, est le moteur de recherche Perplexity. Ici aussi, il est possible d’importer un PDF ou un TXT pour en extraire les données sous forme de texte. Il faudra en revanche les copier-coller. On remporte le même succès avec Copilot (ex-Bing Chat).
- Enfin, on pensera aux outils d’interrogation de documents, comme ChatPDF, qui permet l’extraction des données à partir d’un PDF de plus de 100 pages.
La différence entre ces outils réside non seulement dans la qualité de l’extraction, mais surtout dans les formats de documents importables et exportables.

Déjà abonné ? Connectez-vous...